未提供项目描述

项目描述

多功能性极强的CommonCrawl Extractor






使用CmonCrawl,最灵活的extractor,提供无与伦比的模块化和易用性,释放CommonCrawl数据的全部潜力。
为什么选择CmonCrawl?
CmonCrawl以其独特的功能脱颖而出
- 高模块化:轻松创建满足您特定需求的自定义extractor。
- 全面访问:支持所有CommonCrawl访问方法,包括AWS Athena和CommonCrawl Index API进行查询,以及S3和CommonCrawl API进行下载。
- 灵活实用:可通过命令行界面(CLI)或作为软件开发工具包(SDK)访问,满足您的工作流程偏好。
- 类型安全:注重类型安全,确保您的代码健壮且可靠。
入门指南
安装
从PyPi安装
$ pip install cmoncrawl
从源安装
$ git clone https://github.com/hynky1999/CmonCrawl
$ cd CmonCrawl
$ pip install -r requirements.txt
$ pip install .
使用指南
步骤1:Extractor准备
首先准备您的自定义Extractor。使用以下命令从CommonCrawl数据集中获取示例HTML文件
$ cmon download --match_type=domain --limit=100 html_output example.com html
这将从example.com下载前100个HTML文件,并保存到html_output中。
步骤2:Extractor创建
为您的提取器创建一个新的Python文件,例如 my_extractor.py,并将其放置在 extractors 目录中。按照以下示例实现提取逻辑:
from bs4 import BeautifulSoup
from cmoncrawl.common.types import PipeMetadata
from cmoncrawl.processor.pipeline.extractor import BaseExtractor
class MyExtractor(BaseExtractor):
def __init__(self):
# you can force a specific encoding if you know it
super().__init__(encoding=None)
def extract_soup(self, soup: BeautifulSoup, metadata: PipeMetadata):
# here you can extract the data you want from the soup
# and return a dict with the data you want to save
body = soup.select_one("body")
if body is None:
return None
return {
"body": body.get_text()
}
# You can also override the following methods to drop the files you don't want to extracti
# Return True to keep the file, False to drop it
def filter_raw(self, response: str, metadata: PipeMetadata) -> bool:
return True
def filter_soup(self, soup: BeautifulSoup, metadata: PipeMetadata) -> bool:
return True
# Make sure to instantiate your extractor into extractor variable
# The name must match so that the framework can find it
extractor = MyExtractor()
步骤3:配置创建
设置一个配置文件,config.json,以指定提取器(们)的行为
{
"extractors_path": "./extractors",
"routes": [
{
# Define which url match the extractor, use regex
"regexes": [".*"],
"extractors": [{
"name": "my_extractor",
# You can use since and to choose the extractor based
on the date of the crawl
# You can ommit either of them
"since": "2009-01-01",
"to": "2025-01-01"
}]
},
# More routes here
]
}
请注意,配置文件 config.json 必须是有效的JSON格式。因此,像示例中那样直接在JSON文件中包含注释是不允许的。
步骤4:运行提取器
使用以下命令测试您的提取器:
$ cmon extract config.json extracted_output html_output/*.html html
步骤5:完整爬取和提取
测试完毕后,开始完整的爬取和提取过程
1. 获取要提取的记录列表。
cmon download --match_type=domain --limit=100 dr_output example.com record
这将从 example.com 下载前100条记录并保存在 dr_output 中。默认情况下,每个文件保存100,000条记录,您可以使用 --max_crawls_per_file 选项进行更改。
2. 使用您的自定义提取器处理记录。
$ cmon extract --n_proc=4 config.json extracted_output dr_output/*.jsonl record
注意,您可以使用 --n_proc 选项来指定用于提取的进程数。多进程是在文件级别上进行的,因此如果您只有一个文件,则不会使用它。
处理CommonCrawl错误
在实施任何缓解高错误响应的策略之前,首先检查CommonCrawl网关和S3存储桶的状态非常重要。这可以提供关于可能影响您访问率的任何持续性能问题的宝贵见解。请参考CommonCrawl状态页面了解性能问题的最新更新:[Oct-Nov 2023性能问题](https://commoncrawl.org/blog/oct-nov-2023-performance-issues)。
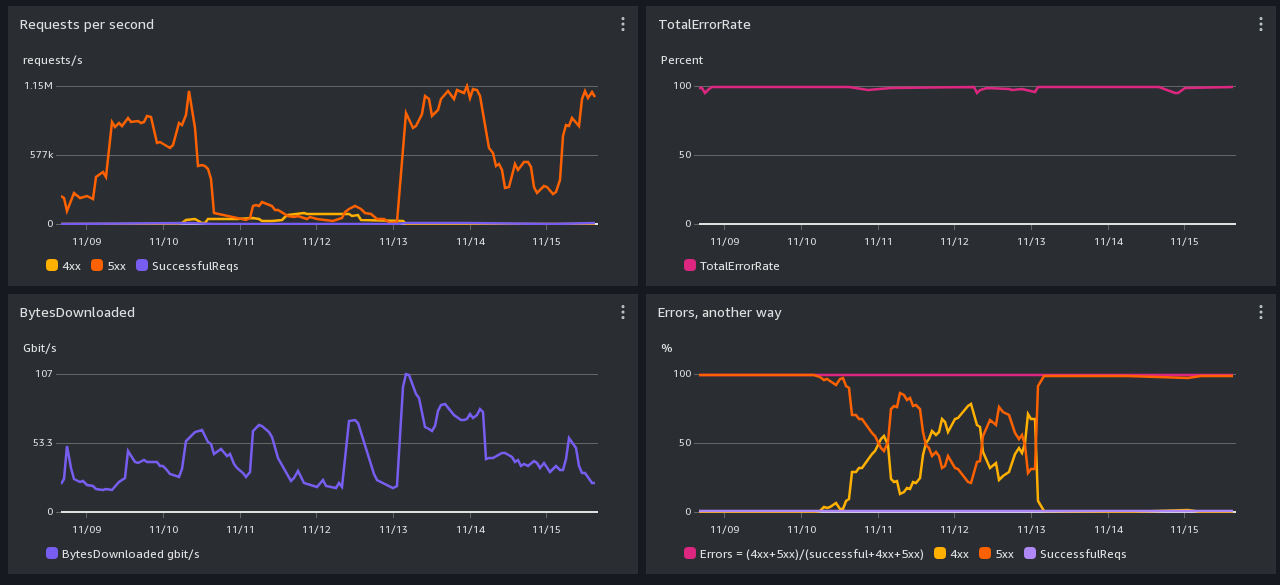
遇到大量错误响应通常表示请求速率过高。为了缓解这种情况,请按照以下顺序考虑以下策略
-
切换到S3访问:而不是使用API网关,选择S3访问,这允许更高的请求速率。
-
调节请求速率:每秒的总请求量由公式
n_proc * max_requests_per_process确定。为了降低请求速率- 减少进程数(
n_proc)。 - 减少每个进程的最大请求量(
max_requests_per_process)。
目标是保持总请求速率低于每秒40次。
- 减少进程数(
-
调整重试设置:如果错误持续
- 增加
max_retry以确保最终数据检索。 - 设置更高的
sleep_base以防止API过度使用并尊重速率限制。
- 增加
高级用法
CmonCrawl 考虑到了灵活性,允许您根据需要定制框架。对于分布式提取和更高级的场景,请参阅我们的[文档](https://hynky1999.github.io/CmonCrawl/)和[CZE-NEC项目](https://github.com/hynky1999/Czech-News-Classification-dataset)。
示例和支持
有关实际示例和进一步的帮助,请访问我们的[示例目录](https://github.com/hynky1999/CmonCrawl/tree/main/examples)。
贡献
加入我们的GitHub[贡献者社区](https://github.com/hynky1999/CmonCrawl)。您的贡献是受欢迎的!
许可证
CmonCrawl 是开源软件,许可协议为MIT。


下载文件
下载适用于您的平台的文件。如果您不确定选择哪个,请了解有关[安装包](https://packaging.pythonlang.cn/tutorials/installing-packages/)的更多信息。
源分布
构建分发
CmonCrawl-1.1.8.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 83b8f95798938382f6fc498a14f257aafa05ceb2357cce0a11f9324d8164b44a |
|
| MD5 | 2b68d1a08eac6e484d0456ca05f35282 |
|
| BLAKE2b-256 | 925ddec4104edbea4dc0139228225a4625be965caba4bbf03b5ba5e0c1826593 |
CmonCrawl-1.1.8-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 099b69600a9f03e043b34a766702cbbb92a069c005b89ce5f6ac16b1957123c1 |
|
| MD5 | 62de87385fd4bc626258b299d7c52e08 |
|
| BLAKE2b-256 | 14a736296c08c68d2f0063c5a43644cabfcd98f068787bcfef19884e417f8832 |