软件开发工具,用于可视化程序运行时的统计信息,并将其与程序阶段关联

项目描述
Chrones 是一个软件开发工具,用于可视化程序运行时的统计信息(CPU百分比,GPU百分比,内存使用情况等),并将其与程序阶段关联。
它的目标是易于使用,并提供开箱即用的有用信息。
以下是 Chrones 生成的一个示例图表,该图表显示了一个启动几个可执行文件的shell脚本的运行时统计信息(请参阅此图像是如何生成的 在Readme的末尾)
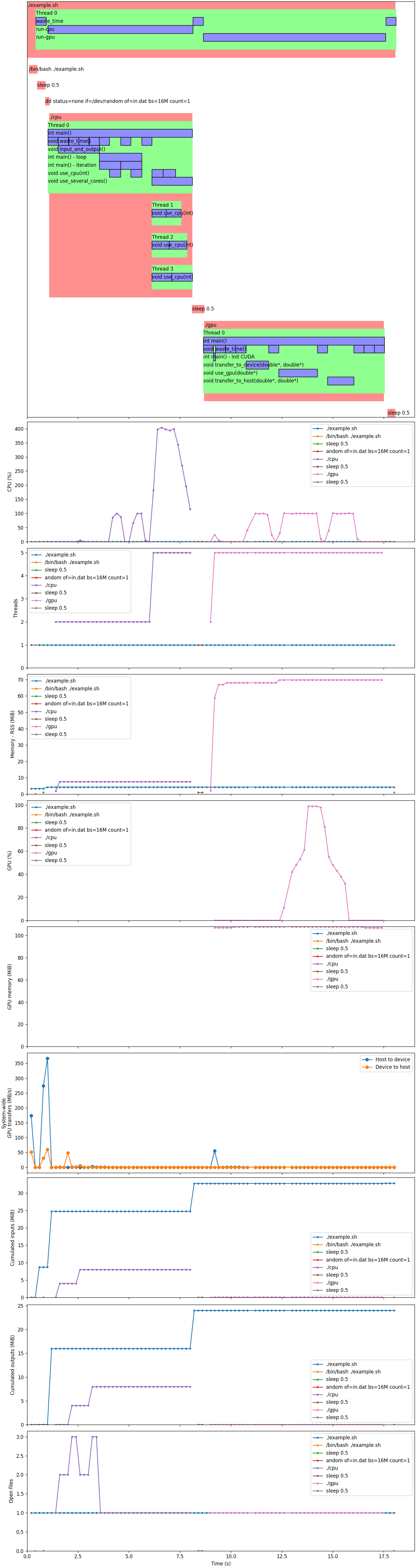
Chrones 由来自 MICS 的 Laurent Cabaret 赞助,并由 Vincent Jacques 编写。
它采用 MIT 许可证。它的 文档和源代码 在 GitHub 上。
概念概述
Chrones 由三部分组成:仪器(可选)、监控和报告。
Chrones 的仪器部分在您修改程序后运行在您的程序内部。它用作您编程语言的库。要使用它,您只需向您想了解的函数中添加一行代码。之后,您的程序将记录这些函数的内部时间信息。
监控部分是您程序的包装器。它会按您的指示运行程序,同时保留其对标准输入和输出的访问、环境以及其命令行的访问。在此过程中,它监控您的程序的整体进程树,并记录资源使用指标。
报告部分读取仪器和监控生成的日志,并生成包含图表的人可读报告。
仪器部分完全可选。您可以在非仪器化程序上使用监控部分,甚至可以在部分仪器化程序上使用,例如调用两个可执行文件的shell脚本,一个仪器化,一个未仪器化。由Chrones报告生成的图表将仅缺少有关程序阶段的信息。
我们选择命令行作为Chrones的主用户界面,以允许轻松集成到您的自动化工作流程中。
请注意,Chrones目前仅在Linux上运行。此外,C++仪器化需要g++。我们非常愿意接受扩展Chrones可用性的贡献。
Chrones的仪器化库适用于C++和shell语言。
预期性能
Chrones的仪器部分可以精确地测量并报告到毫秒的持续时间。其监控部分每秒采样几次。本项目没有纳秒;Chrones非常适合运行至少几秒的程序。
Chrones在C++程序中引入的开销小于每百万个仪器化块一秒。不要用于被调用数十亿次的功能。
开始使用
安装Chrones
Chrones的监控和报告部分作为PyPI上的Python包分发。使用pip install Chrones安装它们。
目前您只需要这些。(点击箭头获取更多信息)
仪器部分按语言特定方式分发。
C++和shell语言实际上没有包管理器,因此C++和shell版本也包含在Python包中。
其他语言的版本将使用适当的包管理器分发。
(可选)仪器化您的代码
概念
仪器化库基于以下概念
协调器
协调器是一个单例对象,它集中测量并将它们写入日志文件。
它还负责启用或禁用仪器化:如果检测到正在Chrones监控内运行,则会创建日志。这可以让您在没有仪器化的情况下运行程序。
Chrone
chrone是主要的仪器化工具。您可以将其视为一个计时器,当它开始时记录一个事件,当它停止时记录另一个事件。
多个chrone可以嵌套。这使得它们特别适合仪器化带有块和函数(即现代程序的大多数)的结构化代码。从嵌套chrone的日志中,Chrones报告能够重建程序的调用堆栈的演变。
Chrones有三个识别属性:一个名称,一个可选的标签和一个可选的索引。这三个在报告中用于区分chrone。以下是它们的含义
- 在支持它的语言中,名称自动从封装函数的名称设置。在不支持的语言中,我们强烈建议您使用相同的约定:chrone的名称来自最近的命名代码块。
- 有时在函数内部仪器化一个块是有意义的。标签用于识别这些块。
- 最后,当这些块是循环的迭代时,您可以使用索引来区分它们。
请参阅此Readme末尾的simple.cpp以获取完整的示例。
特定语言说明
Chrones仪器化库目前适用于以下语言
Shell
首先,导入Chrones并使用以下方式初始化协调器:
source <(chrones instrument shell enable program-name)
其中 program-name 是...您程序的名称。
然后,您可以使用两个函数 chrones_start 和 chrones_stop 来对您的shell函数进行检测
function foo {
chrones_start foo
# Do something
chrones_stop
}
chrones_start 接受一个必选参数:name,以及两个可选参数:label 和 index。请参阅上方 概念 部分的描述。
C++
首先,#include <chrones.hpp>。头文件包含在 Chrones 的 Python 包中。您可以使用 chrones instrument c++ header-location 获取其位置,并将其传递给编译器的 -I 选项。例如,g++ -I`chrones instrument c++ header-location` foo.cpp -o foo。
chrones.hpp 使用带有 __VA_OPT__ 的可变参数宏,因此如果您需要设置 -std 选项,您可以使用 gnu++11、c++20 或更高版本。
在 main 函数之前创建协调器
CHRONABLE("program-name")
其中 program-name 是...您程序的名称。
然后,您可以使用 CHRONE 宏检测函数和块
int main() {
CHRONE();
{
CHRONE("loop");
for (int i = 0; i != 100; ++i) {
CHRONE("iteration", i);
// Do something
}
}
}
CHRONE 宏接受零到两个参数:可选的标签和索引。请参阅上方 概念 部分的描述。在上面的示例中,所有三个 chrones 都将具有相同的名称,即 "int main()"。 "loop" 和 "iteration" 将是最后两个 chrones 的相应标签,并且最后一个 chrone 还将具有索引。
您可以通过将 -DCHRONES_DISABLED 传递给编译器来静态地禁用 Chrones 的检测。在这种情况下,头文件提供的所有宏都将为空,并且您的代码将像不使用 Chrones 一样编译。
故障排除提示:如果您收到 undefined reference to chrones::global_coordinator 错误,请再次检查您是否正在与调用 CHRONABLE 的翻译单元进行链接。
已知限制
CHRONE必须不在main之外使用,例如在静态变量的构造函数和析构函数中
使用 chrones run 运行
如有必要,编译您的可执行文件。然后使用 chrones run -- your_program --with --its --options 启动它们,或者如果您使用的是 NVidia GPU,则使用 chrones run --monitor-gpu -- your_program。
在 -- 之前的所有内容都被解释为 chrones run 的选项。之后的所有内容都将原样传递给您的程序。标准输入和输出将被不变地传递给您的程序。`chrones run` 的退出代码是 `your_program` 的退出代码。
请查看 chrones run --help 了解其详细用法。
生成报告
运行 chrones report 在当前目录中生成报告。
请查看 chrones report --help 了解其详细用法。
示例图像的代码
作为一个完整的示例,这里是有关于本 Readme 文件顶部图像的 shell 脚本(命名为 example.sh)
source <(chrones instrument shell enable example)
function waste_time {
chrones_start waste_time
sleep 0.5
chrones_stop
}
waste_time
dd status=none if=/dev/random of=in.dat bs=16M count=1
chrones_start run-cpu
./cpu
chrones_stop
waste_time
chrones_start run-gpu
./gpu
chrones_stop
waste_time
以及脚本调用的两个可执行文件
cpu.cpp:
#include <time.h>
#include <chrones.hpp>
CHRONABLE("cpu");
void waste_time() {
CHRONE();
usleep(500'000);
}
void input_and_output() {
CHRONE();
char data[4 * 1024 * 1024];
std::ifstream in("in.dat");
for (int i = 0; i != 2; ++i) {
in.read(data, sizeof(data));
waste_time();
std::ofstream out("out.dat");
out.write(data, sizeof(data));
waste_time();
}
}
void use_cpu(const int repetitions) {
CHRONE();
for (int i = 0; i < repetitions; ++i) {
volatile double x = 3.14;
for (int j = 0; j != 1'000'000; ++j) {
x = x * j;
}
}
}
void use_several_cores() {
CHRONE();
#pragma omp parallel for
for (int i = 0; i != 8; ++i) {
use_cpu(256 + i * 32);
}
}
int main() {
CHRONE();
waste_time();
input_and_output();
{
CHRONE("loop");
for (int i = 0; i != 2; ++i) {
CHRONE("iteration", i);
waste_time();
use_cpu(256);
}
}
waste_time();
use_several_cores();
}
gpu.cu:
#include <cassert>
#include <chrones.hpp>
const int block_size = 1024;
const int blocks_count = 128;
const int data_size = blocks_count * block_size;
CHRONABLE("gpu");
void waste_time() {
CHRONE();
usleep(500'000);
}
void transfer_to_device(double* h, double* d) {
CHRONE();
for (int i = 0; i != 8'000'000; ++i) {
cudaMemcpy(h, d, data_size * sizeof(double), cudaMemcpyHostToDevice);
}
cudaDeviceSynchronize();
}
__global__ void use_gpu_(double* data) {
const int i = blockIdx.x * block_size + threadIdx.x;
assert(i < data_size);
volatile double x = 3.14;
for (int j = 0; j != 700'000; ++j) {
x = x * j;
}
data[i] *= x;
}
void use_gpu(double* data) {
CHRONE();
use_gpu_<<<blocks_count, block_size>>>(data);
cudaDeviceSynchronize();
}
void transfer_to_host(double* d, double* h) {
CHRONE();
for (int i = 0; i != 8'000'000; ++i) {
cudaMemcpy(d, h, data_size * sizeof(double), cudaMemcpyDeviceToHost);
}
cudaDeviceSynchronize();
}
int main() {
CHRONE();
waste_time();
{
CHRONE("Init CUDA");
cudaFree(0);
}
waste_time();
double* h = (double*)malloc(data_size * sizeof(double));
for (int i = 0; i != data_size; ++i) {
h[i] = i;
}
waste_time();
double* d;
cudaMalloc(&d, data_size * sizeof(double));
waste_time();
transfer_to_device(h, d);
waste_time();
use_gpu(d);
waste_time();
transfer_to_host(d, h);
waste_time();
cudaFree(d);
waste_time();
free(h);
waste_time();
}
此代码使用 make 和以下 Makefile 构建
all: cpu gpu
cpu: cpu.cpp
g++ -fopenmp -O3 -I`chrones instrument c++ header-location` cpu.cpp -o cpu
gpu: gpu.cu
nvcc -O3 -I`chrones instrument c++ header-location` gpu.cu -o gpu
它将这样执行
OMP_NUM_THREADS=4 chrones run --monitor-gpu -- ./example.sh
报告将这样创建
chrones report
已知限制
检测的影响
将检测添加到您的程序将改变监控数据所观察到的
- 数据持续输出到日志文件,并在报告的 "I/O" 图中可见
- 日志文件也被计入 "打开的文件" 图
- 在 C++ 中,您的进程中将启动一个额外的线程,在 "线程" 图中可见
非单调系统时钟
Chrones 对闰秒处理得不好。但谁又处理得好呢?
多个 GPU
尚未支持具有多个 GPU 的机器。
开发 Chrones
您需要一个装有
- 合理新版本的 Docker
- 合理新版本的 Bash
哦,目前您需要一个已安装驱动程序并配置了 nvidia-container-runtime 的 NVidia GPU。
构建所有内容并运行所有测试
./run-development-cycle.sh
点击 更新版本号 并在 PyPI 上发布
./publish.sh [patch|minor|major]


下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解有关 安装包 的更多信息。
源代码分发
构建分发
Chrones-1.1.1.tar.gz 的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 5bbfd1899a7b2993d67e2c86eb38e223033bacfcd0f422f73a6f2e9a4569eb71 |
|
| MD5 | a1dc1f4b60f99673bdec42ec89a6643d |
|
| BLAKE2b-256 | f41152a70cf6a10255e01c2d4bc54d83cae265593d62a2d721ea8eaa2aea9f89 |
Chrones-1.1.1-py3-none-any.whl 的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 450513f3741f5590caeac063458cc1401c9b987c67ba56b6fcca825088d3bb86 |
|
| MD5 | fe682ab003ea1b1b9aaa9e2c5fbf5e7f |
|
| BLAKE2b-256 | 11f207be72aed76d957332c549e114f488fbbe095a81c0a52934d836fc711683 |