主动学习Python包


项目描述

简介
cardinal是一个Python包,用于执行和监控利用各种查询采样方法和指标进行的主动学习实验。
该项目目前由Dataiku的研究团队维护。
入门
Cardinal丰富的文档提供了一些示例,帮助您开始使用主动学习。
- 最低置信度与随机采样展示了基本的主动学习流程,并解释了为什么它比随机采样更好。
- 最低置信度与KMeans采样展示了更高级的技术。
- 数字识别和指标上的主动学习展示了在MNIST数据集上的实验,并提出了一些指标来估计实验期间的准确度提升。
主动学习
主动学习的目标是优化给定成本下未标记样本的标记。
典型的主动学习工作流程如下:
- 收集未标记数据
- 从这些未标记数据中,实验者选择样本进行标注
- 将这些样本提交给预言者进行标记
- 根据新标签和旧标签训练模型
- 如果模型被认为足够好或者没有更多预算,模型将交付生产
- 否则,实验者将利用对模型的了解来选择下一个需要标注的样本
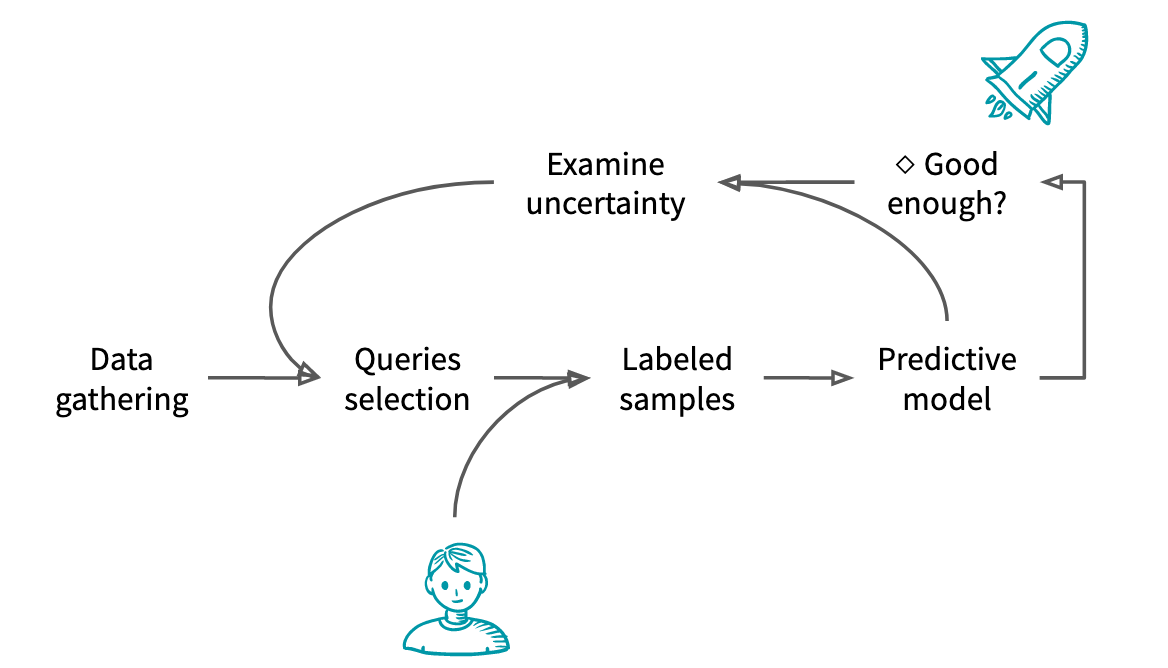
主动学习的挑战主要在于
- 从模型中提取信息。 方法可能因模型和用例而异。
- 一次性选择多个样本。 假设每次标注后模型都可以重新训练是不现实的。
- 最大限度地利用未标注信息。 在主动学习环境中,实验者通常面临比标注能力更大的未标注数据量。
启动with cardinal
设X_unlabeled为待标注的未标注数据集,而(X_labeled, y_labeled)为原始标注数据,用于训练我们的模型。一次主动学习迭代可以表示为
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from cardinal.uncertainty import ConfidenceSampler
model = RandomForestClassifier()
batch_size = 20
sampler = ConfidenceSampler(model, batch_size)
model.fit(X_labelled, y_labelled)
sampler.fit(X_labelled, y_labelled)
selected = sampler.select_samples(X_unlabelled)
#Updating the labeled and unlabeled pool
X_labelled = np.concatenate([X_labelled, selected])
#The selected samples are sent to be labeled as y_selected
y_labelled = np.concatenate([y_labelled, y_selected])
但是如何评估主动学习过程的表现呢?
主动学习有两种形式:带有固定测试集和带有增量测试集。前者在主动学习文献的固定环境中几乎总是唯一被提出的,而后者在现实中更为常见。
- 在固定测试集中,已经有了足够大且具有代表性的测试集来处理当前的任务。这相当于模型已经被训练和测试,甚至可能已经部署的情况。随着新数据的到来,机器学习从业者可以用现有模型对其进行评分或手动标注。相同的测试集将用于评估潜在的额外性能提升。
设(X_test, y_test)表示固定测试集。那么上述内容变为
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from cardinal.uncertainty import ConfidenceSampler
model = RandomForestClassifier()
batch_size = 20
sampler = ConfidenceSampler(model, batch_size)
accuracies = []
model.fit(X_labelled, y_labelled)
sampler.fit(X_labelled, y_labelled)
selected = sampler.select_samples(X_unlabelled)
# Evaluating performance
accuracies.append(model.score(X_test, y_test))
# Updating the labeled and unlabeled pool
X_labelled = np.concatenate([X_labelled, selected])
# The selected samples are sent to be labeled as y_selected
y_labelled = np.concatenate([y_labelled, y_selected])
- 当开始一个新的机器学习项目并且需要收集和标注数据时,我们处于增量测试集环境。没有已标注的基准数据集开始,新标注数据的一部分将构成每个标注迭代的测试集。这是相应的主动学习迭代
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from cardinal.uncertainty import ConfidenceSampler
from sklearn.model_selection import train_test_split
model = RandomForestClassifier()
batch_size = 20
sampler = ConfidenceSampler(model, batch_size)
accuracies = []
X_train, X_test, y_train, y_test = train_test_split(X_labelled, y_labelled, test_size=0.2, random_state=123)
model.fit(X_train, y_train)
sampler.fit(X_train, y_train)
selected = sampler.select_samples(X_unlabelled)
# Evaluating performance
accuracies.append(model.score(X_test, y_test))
# Updating the labeled and unlabeled pool
X_labelled = np.concatenate([X_labelled, selected])
# The selected samples are sent to be labeled as y_selected
y_labelled = np.concatenate([y_labelled, y_selected])
需要注意的是,与文献或我们的文档中的漂亮的学习曲线相反,在这种情况下,当使用小样本量时,它可能是非单调的。
另一个主动学习包?
已经存在几个出色的主动学习包,你可以在以下博客文章中找到我们对它们的看法在这里。截至今天,cardinal与它们中的大多数非常相似,那么为什么还要在生态系统中添加一个新的包呢?
在cardinal中,我们的目标是赋予用户在实际环境中的最大控制权。在cardinal中,我们旨在提供简单的方法,这些方法在各种情况下都已被证明是有用的。例如,我们决定提出最近Zdhanov的Diverse Mini-Batch Active Learning方法,因为它依赖于聚类,这是在参考主动学习论文(Xu2007)中已经提出的一个想法,它基于众所周知的KMeans算法,并且我们能够在小和大数据集上复制大部分发现。
在未来,我们旨在解决我们知道其他包没有涉及的问题
- 变化批量大小。 大多数其他包都假设批量大小在所有迭代中都是相同的,这与我们在该方面的经验相矛盾。我们目前正在研究设计用于提供最佳见解的指标,即使批量大小在实验过程中发生变化。
- 混合多种方法。 主动学习方法通常涉及最大限度地利用来自不同信息来源的优势。一些最新的论文使用半监督学习和自训练的组合。我们希望在我们的包中实现这一点。
安装
依赖关系
cardinal依赖于
- Python >= 3.5
- NumPy >= 1.11
- SciPy >= 0.19
- scikit-learn >= 0.19(可选)
- matplotlib >= 2.0(可选)
- apricot-select >= 0.5.0(可选)
通过不同的选项,cardinal提供额外的功能
sklearn需要scikit-learn,并提供基于KMeans的采样器和批处理方法submodular需要apricot-select和scikit-learn。它允许使用基于子模设施位置问题的查询采样器。examples需要scikit-learn、apricot-select和matplotlib。它提供绘图能力和运行示例所需的所有包。all包含上述所有内容。
使用pip安装
安装cardinal最简单的方法是使用pip。对于常规安装,只需键入
pip install -U cardinal
可选依赖项也以以下方式由pip处理
pip install -U 'cardinal[option]'
option可以是以下之一
- sklearn以启用基于聚类等的scikit-learn相关采样器
- submodular安装apricot-select以运行子模采样器
- examples安装运行示例所需的所有依赖项
- doc安装生成基于sphinx的文档所需的依赖项
- all安装上述所有内容
贡献
欢迎贡献。查看我们的贡献指南。


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。
源分布
构建分布
cardinal-0.0.9.tar.gz的散列
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | d511258f9e242dcfb54aabcd6fdaece9f235846bfae66a391e5203b3d6a401fe |
|
| MD5 | dd732a9fd1e74a14a551612c220afa1b |
|
| BLAKE2b-256 | 1e1298e6aa7f14ef0e7370c08bcf7e423fb95ddcfa2237326d561720eafed0b9 |
cardinal-0.0.9-py3-none-any.whl的散列
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | f6f1d73d873acefd33d9785b51da1c3558551b3feadc2efd665da49c36752093 |
|
| MD5 | fb34df8674615b05c1293675f3839f75 |
|
| BLAKE2b-256 | 2fe4a8ac7d84d425688da7c8494563cb1684eeb9ebb95b10a31dd702d433f7f5 |







