使用NumPy风格的语法操作类似JSON的数据。

项目描述

Awkward Array 是一个用于处理嵌套、可变大小数据的库,包括任意长度的列表、记录、混合类型和缺失数据,使用 NumPy-like idioms。
数组是 动态类型 的,但对其操作是 编译和快速 的。当数组维度规则时,其行为与NumPy一致,当维度不规则时,则进行推广。
激励示例
给定一个具有 x、y 字段和变量长度嵌套列表的对象数组
array = ak.Array([
[{"x": 1.1, "y": [1]}, {"x": 2.2, "y": [1, 2]}, {"x": 3.3, "y": [1, 2, 3]}],
[],
[{"x": 4.4, "y": {1, 2, 3, 4]}, {"x": 5.5, "y": [1, 2, 3, 4, 5]}]
])
以下代码提取 y 值,从每个内部列表中删除第一个元素,并在剩余的所有内容上运行NumPy的 np.square 函数
output = np.square(array["y", ..., 1:])
结果是
[
[[], [4], [4, 9]],
[],
[[4, 9, 16], [4, 9, 16, 25]]
]
仅使用Python的等效代码
output = []
for sublist in array:
tmp1 = []
for record in sublist:
tmp2 = []
for number in record["y"][1:]:
tmp2.append(np.square(number))
tmp1.append(tmp2)
output.append(tmp1)
使用Awkward Arrays的表达式不仅更加简洁,使用了来自NumPy的熟悉语法,而且速度更快,使用的内存更少。
对于比上述问题大10倍的问题(在单线程2.2 GHz处理器上),
- Awkward Array的单行代码运行需要 4.6秒,使用 2.1GB 的内存,
- 使用Python列表和字典的等效代码需要 138秒 来运行,使用 22GB 的内存。
速度和内存因数达到两位数是常见的,因为我们正在用类型专门的预编译例程替换Python的动态类型、指针追踪的虚拟机,以处理连续数据。(换句话说,与NumPy的原因相同。)当Awkward Array与Numba配合使用时,还可以实现更高的速度提升。
我们的SciPy 2020会议演示提供了一个很好的介绍,展示了如何在实际分析中使用这些数组。
安装
Awkward Array可以通过pip从PyPI安装。
pip install awkward
根据您的操作系统和Python版本,您可能会得到预编译的二进制文件(wheel)。如果没有,pip将尝试从源代码编译(这需要C++编译器、make和CMake)。
Awkward Array还可以通过conda使用,它始终安装二进制文件
conda install -c conda-forge awkward
如果您已经将conda-forge添加为频道,则无需使用-c conda-forge。建议添加该频道,因为它确保您的所有软件包使用兼容的版本
conda config --add channels conda-forge
conda update --all
获取帮助
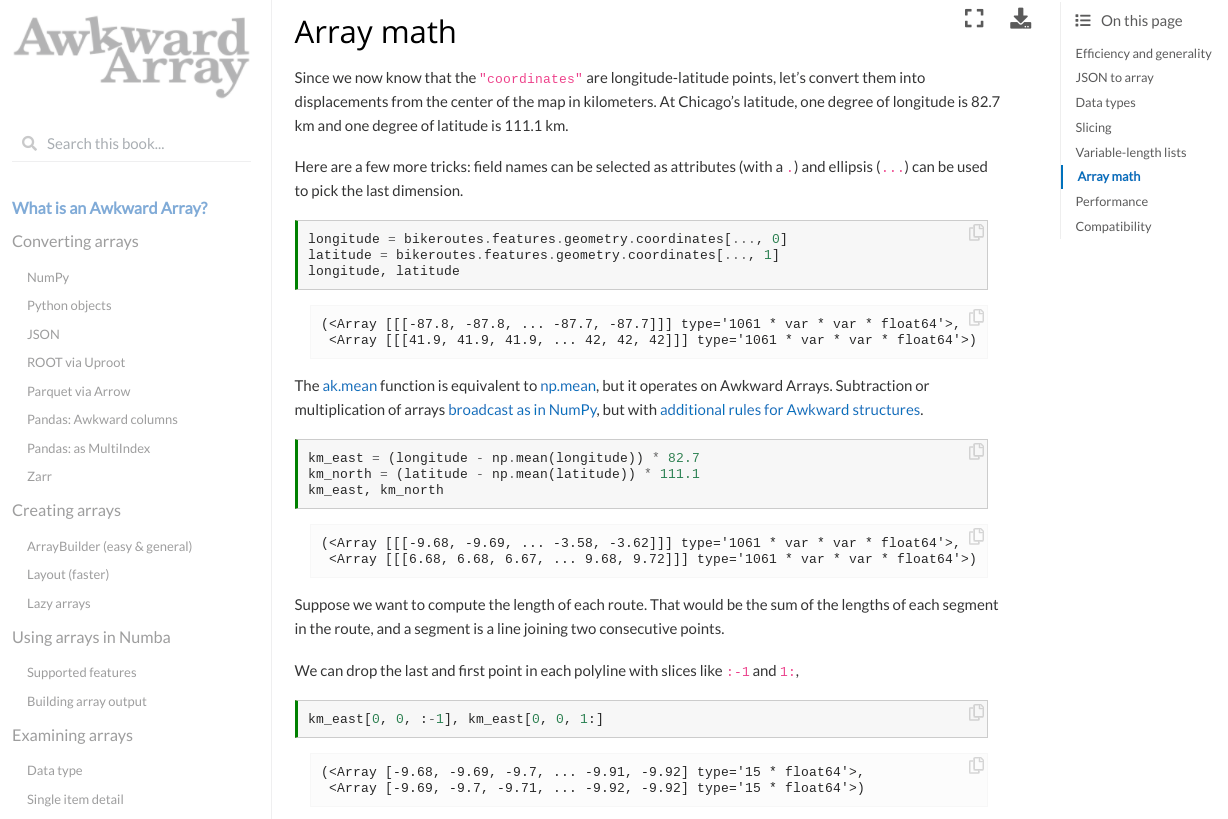
|
|
- 在GitHub Issues上报告错误、请求功能以及要求额外的文档。
- 如果您有一个“我该如何...?”的问题,请在带有[awkward-array]标签的StackOverflow上提问。务必包括您使用的任何其他库的标签,例如Pandas或PyTorch。
- 要实时提问,请尝试Gitter Scikit-HEP/awkward-array聊天室。


下载文件
下载您平台的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源代码分发
构建分发
awkward1-1.0.0.tar.gz的散列
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 4e51fed29c3a3618cdc07719ff3d1cdd1d567643f9629532bd7d965f9fb76c50 |
|
| MD5 | f44c6acb4c165d5f468a4322882f2acc |
|
| BLAKE2b-256 | 05e1de4607482cd18eb43bfb4c7381571ad0928f7ebf0ed5815f93b21cc5e46a |