多实例学习的自适应池化算子


项目描述
autopool
多实例学习(MIL)的自适应池化算子(文档)。




AutoPool是一个自适应(可训练)的池化算子,它可以在常见的池化算子之间平滑插值,例如最小值、最大值或平均值池化,自动适应数据的特征。
AutoPool可以轻松应用于任何用于时间序列标签预测的可微模型。AutoPool在以下论文中提出,其中它被用于与卷积神经网络结合进行声音事件检测的评估
弱标签声音事件检测的自适应池化算子
Brian Mcfee,Justin Salamon,和Juan Pablo Bello
IEEE Transactions on Audio, Speech and Language Processing,待出版,2018。
安装
要安装基于keras的实现
python -m pip install autopool[keras]
对于基于tensorflow的实现
python -m pip install autopool[tf]
定义
AutoPool通过添加一个要与其他所有可训练模型参数一起学习的可训练参数α来扩展softmax加权池化
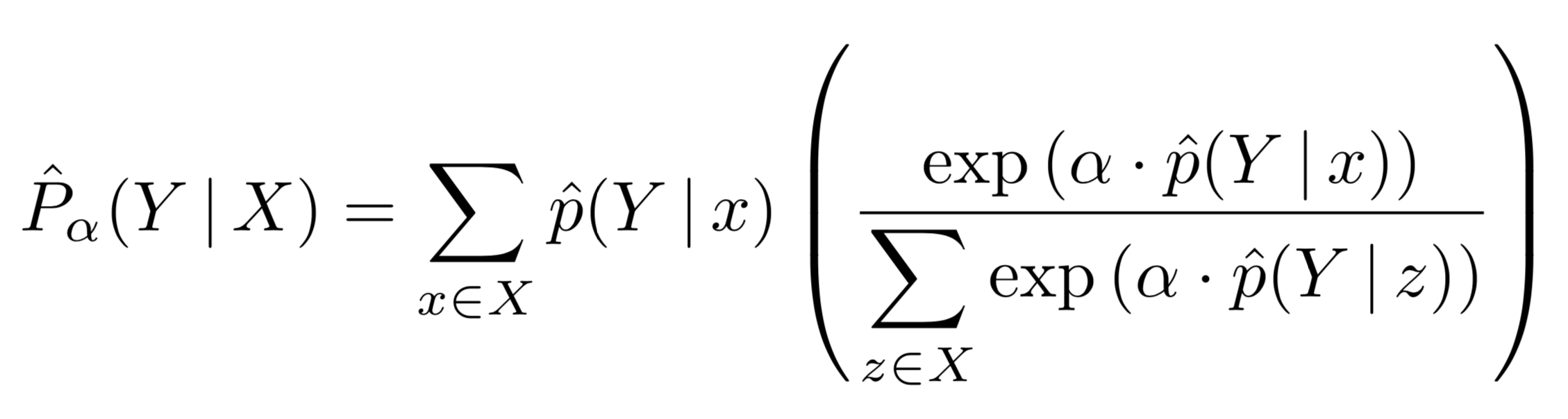
在这里,p(Y|x) 表示实例 x 的预测,而 X 表示实例集合(包)。聚合预测 P(Y|X) 是实例级预测的加权平均值。注意,当 α = 0 时,这会降低为无权平均值;当 α = 1 时,这简化为 soft-max 池化;当 α → ∞ 时,这接近 max 操作符。因此得名:AutoPool。
用法
AutoPool 以 keras 层的形式实现,因此使用它就像使用任何标准 Keras 池化层一样简单,例如
from autpool.keras import AutoPool1D
bag_pred = AutoPool1D(axis=1)(instance_pred)
更详细的信息和示例请参阅 文档。
约束和正则化 AutoPool
在 论文 中,我们展示了限制 α 的取值范围或对 α 应用 l2 正则化可能带来的好处;这分别导致了约束 AutoPool(CAP)和正则化 AutoPool(RAP)。由于 AutoPool 以 keras 层的形式实现,CAP 和 RAP 可以通过层的可选参数实现
CAP 使用非负 α
bag_pred = AutoPool1D(axis=1, kernel_constraint=keras.constraints.non_neg())(instance_pred)
CAP 将 α 的范数约束为某个值 alpha_max
bag_pred = AutoPool1D(axis=1, kernel_constraint=keras.constraints.max_norm(alpha_max, axis=0))(instance_pred)
关于确定合理的 alpha_max 值的启发式方法在论文中给出(第 III.E 节)。
RAP 使用 l2 正则化的 α
bag_pred = AutoPool1D(axis=1, kernel_regularizer=keras.regularizers.l2(l=1e-4))(instance_pred)
CAP 和 RAP 可以通过应用内核约束和内核正则化来组合。
如果使用基于 tensorflow 的实现,所有上述方法都将有效,除了应将 keras 替换为 tensorflow.keras(或 tf.keras),例如
import tensorflow as tf
from autopool.tf import AutoPool1D
bag_pred = AutoPool1D(axis=1, kernel_regularizer=tf.keras.regularizers.l2(l=1e-4))(instance_pred)
多标签
AutoPool 可以直接推广到多标签设置,其中可能将多个类别标签应用于每个实例 x(例如,实例中可能同时存在“汽车”和“汽笛”)。在这种情况下,为每个类别应用单独的自动池化操作符。而不是单个参数 α,存在一个参数向量 α_c,其中 c 是输出词汇表的索引。这允许联合训练的模型独立地为每个类别调整池化策略。请参阅 论文 以获取更多详细信息。


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解更多关于 安装包 的信息。