在不牺牲效率和性能的情况下,将LLMs扩展到无限长度,无需重新训练

项目描述
Transformer中的注意力点,用于无限流畅生成
TL;DR: attention_sinks通过使用修改后的滑动窗口注意力,使预训练的LLM能够无限期地生成流畅的文本。
基准测试结果
有关这些基准测试如何执行的信息,请参阅基准设置。
困惑度
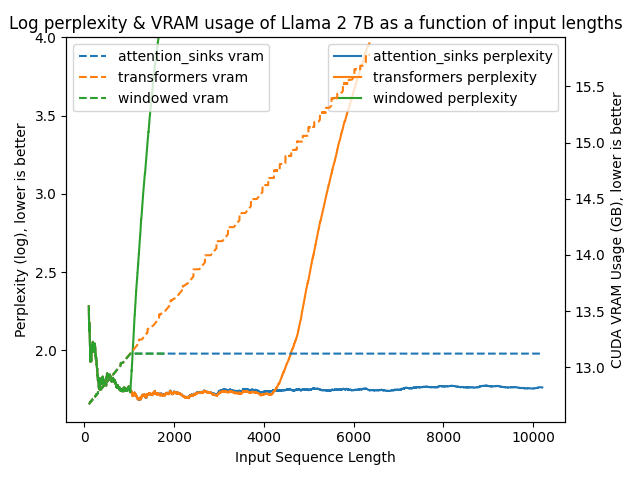
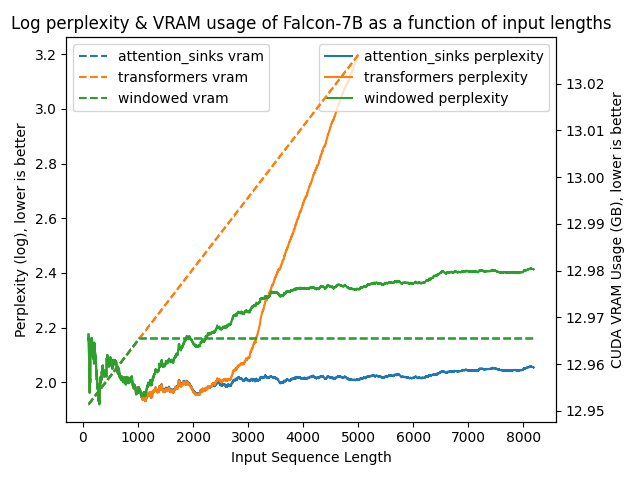
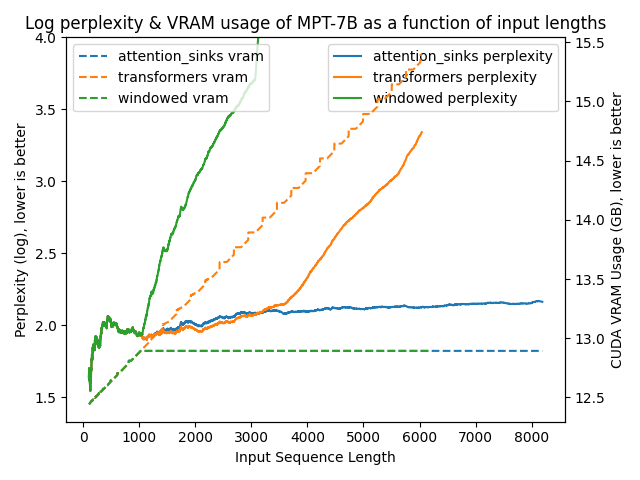
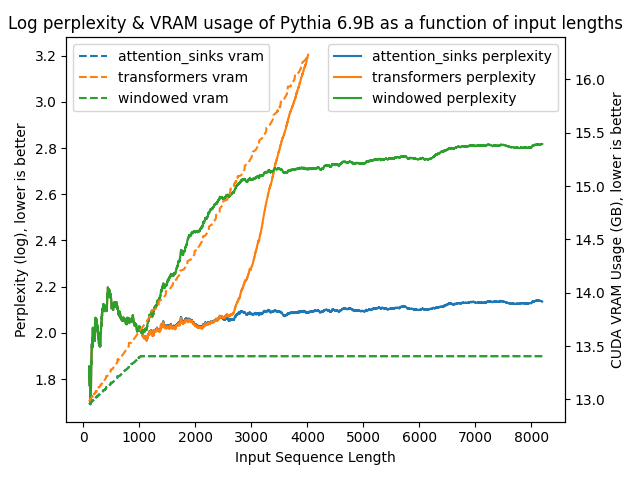
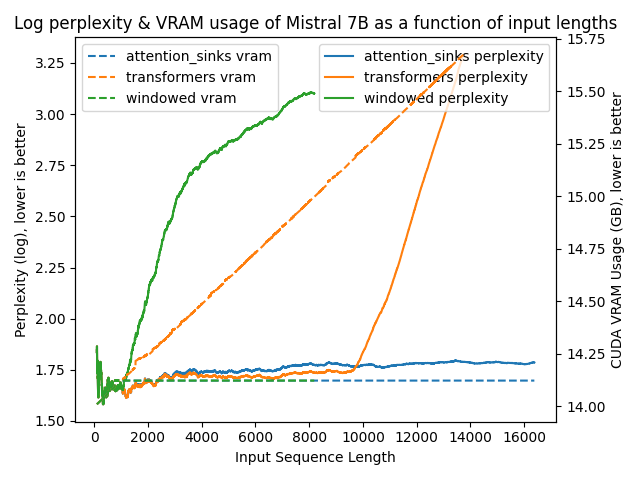
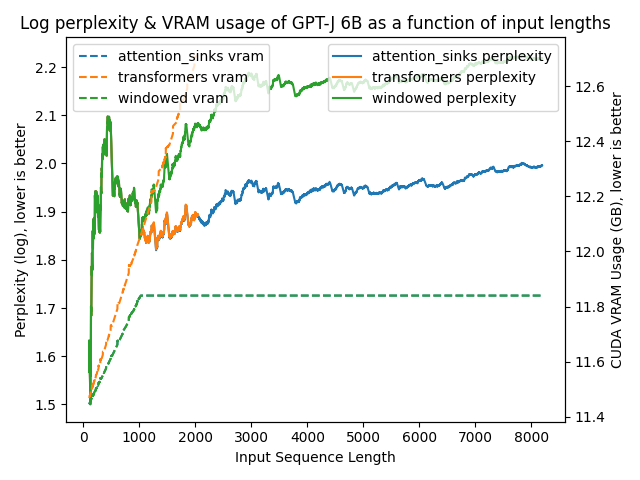
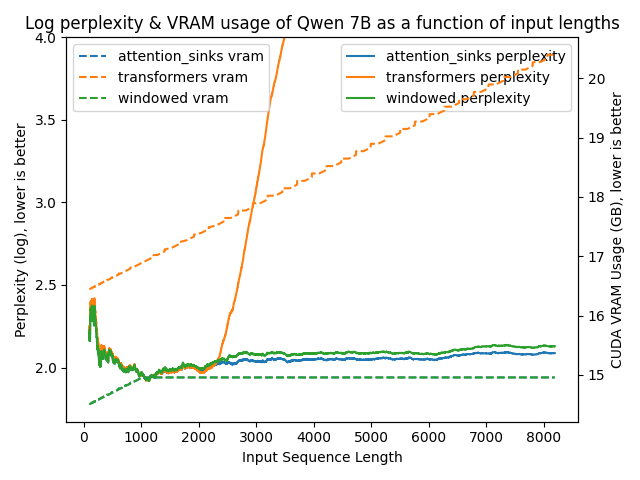
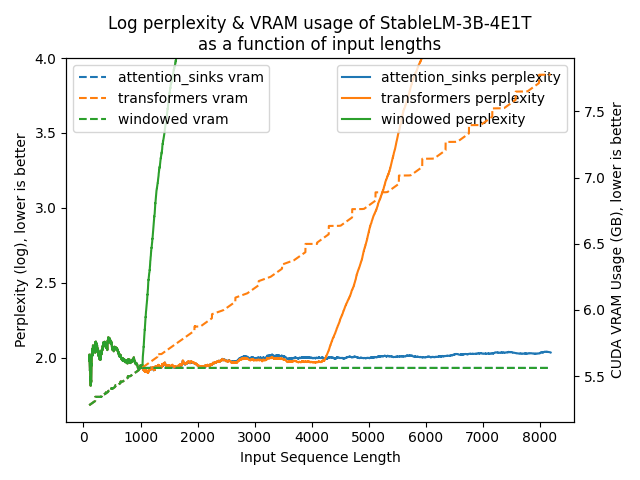
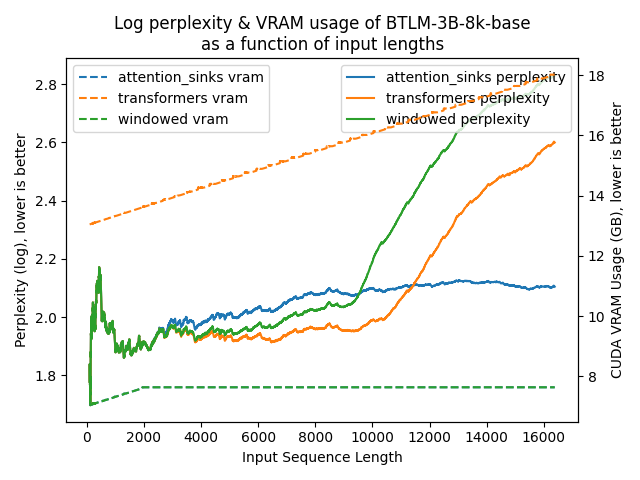
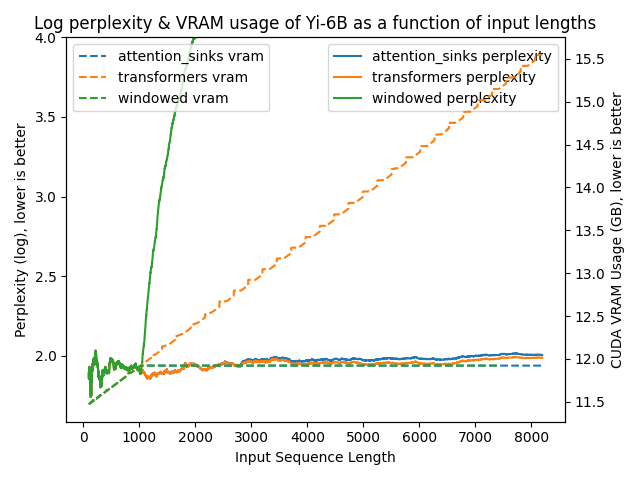
以下图表展示了在不同方法下模型的困惑度。更高的困惑度表明模型正在失去产生适当语言的能力。
| Llama-2-7b-hf | Falcon-7B |
|---|---|
 |
 |
| MPT-7B | Pythia-6.9B |
 |
 |
| Mistral-7B-v0.1 | GPT-J-6B |
 |
 |
| Qwen-7B | StableLM-3B-4E1T |
 |
 |
| BTLM-3B-8k-base | Yi-6B |
 |
 |
结果一目了然
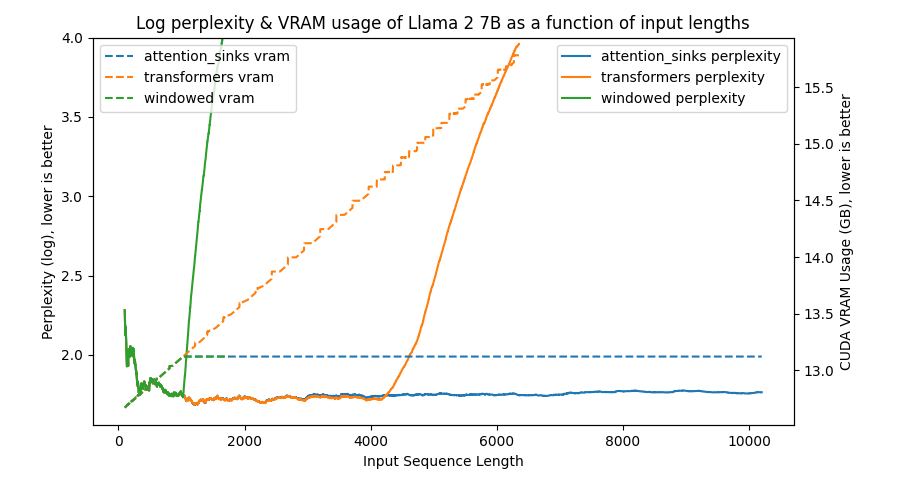
transformers: 由于没有进行窗口操作,VRAM使用量呈线性增长。在预训练长度之后,性能大幅下降。windowed: 由于在1024个标记处进行窗口操作,VRAM使用量保持恒定。然而,一旦第一个标记离开窗口,性能就会下降。attention_sinks: 由于使用4个注意力点标记和1020个最近的标记进行窗口操作,VRAM使用量保持恒定。尽管VRAM使用量保持恒定,但这种方法从未失败。
无限生成过程中的流畅度
请在此处查看使用相同设置但通过以下方式加载的同一Llama 2 7B模型生成的文本:
transformers: 在约1900个标记后失去流畅度,并开始无限期地生成如🤖🧠👨���������������������❌ 这样的损坏的Unicode字符。窗口注意力:在约1000个标记后失去流畅性,生成带有文本如OOOMMO̶OANOOAMOO̶OMMO❌的数百个新行。注意力消减:在整个10k个标记的测试中流畅✅。
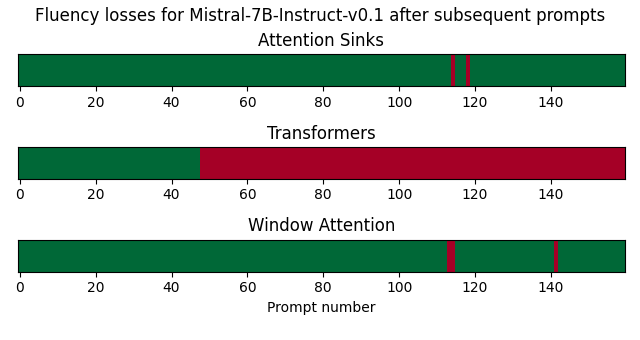
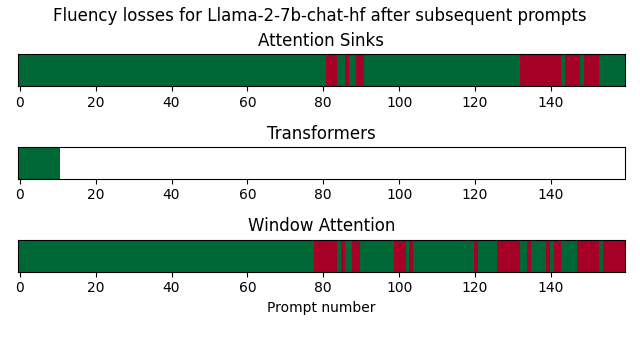
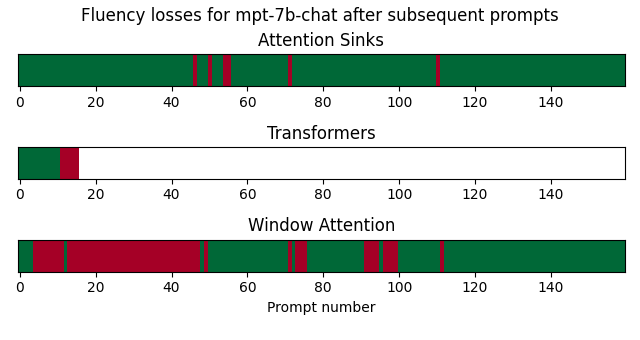
后续提示中聊天式LLM的流畅性
在这个基准测试中,我通过模型发送了来自MT-Bench的后续提示,并自动检测流畅性何时丢失。
[!警告] 自动检测流畅性丢失的方法非常简单:它试图计算响应中的真实单词数量,但如果例如提示是生成一些德语文本,则可能会导致假阳性。请参阅demo/streaming_logs以获取完整的日志,以更好地了解实际的生成性能。
对于Llama-2-7b-chat,由于transformers耗尽了VRAM,因此它只能处理少量后续提示。对于MPT-7B-chat,当输入长度超过2048时,会遇到RuntimeError,除非将最大序列长度配置为更高的值。在这个实验中,我将MPT-7B-chat的设置调整为8192。对于Zephyr-7B-alpha,当生成速度过慢时停止生成。
| Mistral-7B-Instruct-v0.1 | Llama-2-7b-chat-hf |
|---|---|
 |
 |
| MPT-7B-chat | Zephyr-7B-alpha |
 |
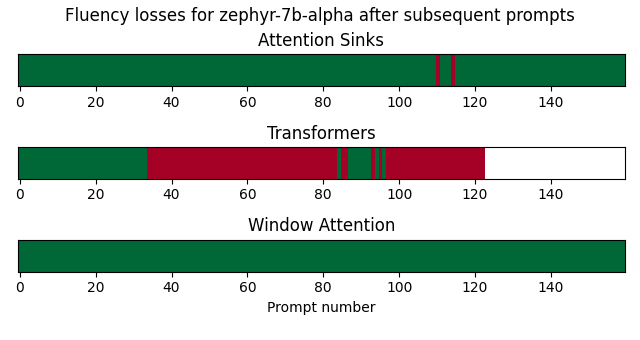 |
使用注意力消减加载模型对后续提示的模型流畅性有非常积极的影响。然而,正如Llama-2-7B-chat-hf所示,它并不能完全避免流畅性问题。
概述
此存储库是Efficient Streaming Language Models with Attention Sinks论文的开源实现。
- 扩展现有的LLM(例如Llama 2),在不牺牲效率性能的情况下无限期地生成流畅文本,而无需任何重新训练。非常适合多步骤LLM,例如聊天助手。
- 即使在400万个标记之后,模型困惑度仍然稳定!
- 与常规
transformers不同,内存使用量是恒定的,因此推理不会因内存问题而在较长序列长度时变得非常慢。 - 使用注意力消减的模型已被证明在从20行前召回值任务上表现良好,即使模型已经处理了数十万行,而使用常规密集或窗口注意力的模型在处理几千个标记后困惑度会降至0%。
attention_sinksAPI允许直接替换transformersAPIfrom attention_sinks import AutoModel model = AutoModel.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="auto")
- 支持Llama、Mistral、Falcon、MPT、GPTNeoX (Pythia)、GPT-J、Qwen、StableLM_epoch、BTLM和Yi模型。
- 对
AutoModelForCausalLM.from_pretrained的新参数attention_sink_size,int,默认值为4:用作注意力消减的初始标记数。这些标记始终包含在注意力消减KV缓存中。attention_sink_window_size,int,默认值为1020:滑动窗口的大小,即包含在注意力消减KV缓存中的“近期标记”数量。更大的窗口大小会消耗更多内存。
有关更多详细信息,请参阅常见问题解答。
安装
您可以像这样安装attention_sinks
pip install attention_sinks
使用方法
加载任何Llama、Mistral、Falcon、MPT、GPTNeoX (Pythia)、GPT-J、Qwen、StableLM_epoch、BTLM或Yi模型就像在transformers中加载它一样简单,唯一的区别是模型类必须从attention_sinks而不是transformers中导入,例如。
from attention_sinks import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b", device_map="auto")
生成可以像从transformers中期望的那样进行,例如像这样。
import torch
from transformers import AutoTokenizer, TextStreamer, GenerationConfig
from attention_sinks import AutoModelForCausalLM
# model_id = "meta-llama/Llama-2-7b-hf"
# model_id = "mistralai/Mistral-7B-v0.1"
model_id = "mosaicml/mpt-7b"
# model_id = "tiiuae/falcon-7b"
# model_id = "EleutherAI/pythia-6.9b-deduped"
# Note: instruct or chat models also work.
# Load the chosen model and corresponding tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_id,
# for efficiency:
device_map="auto",
torch_dtype=torch.float16,
# `attention_sinks`-specific arguments:
attention_sink_size=4,
attention_sink_window_size=252, # <- Low for the sake of faster generation
)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
# Our input text
text = "Vaswani et al. (2017) introduced the Transformers"
# Encode the text
input_ids = tokenizer.encode(text, return_tensors="pt").to(model.device)
with torch.no_grad():
# A TextStreamer prints tokens as they're being generated
streamer = TextStreamer(tokenizer)
generated_tokens = model.generate(
input_ids,
generation_config=GenerationConfig(
# use_cache=True is required, the rest can be changed up.
use_cache=True,
min_new_tokens=100_000,
max_new_tokens=1_000_000,
penalty_alpha=0.6,
top_k=5,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
),
streamer=streamer,
)
# Decode the final generated text
output_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
本例将愉快地生成100k到1m个token,而不会忘记如何说话,即使在像Google Colab这样的低VRAM环境中,只要在AutoModelForCausalLM.from_pretrained中使用load_in_4bit=True。
演示
您可以在demo/endless_generation.py中找到这个无限生成的演示脚本。我已经运行了这个脚本几次,生成了最多10000个token的日志,使用了Llama 2 7B,并分别以attention_sinks、transformers和windowed(注意力)进行记录。生成设置不是最佳,但日志清楚地表明,带有attention_sinks的Llama 2 7B是唯一能够生成流畅文本的方法。
然而,如果您想进行多步生成,这对于attention_sinks模型来说很合适,那么您应该尝试demo/streaming.py演示。这种方法是必需的,因为常规的model.generate不返回所需的past_key_values参数,该参数将被用作下一个提示的历史记录。
基准设置
困惑度
我通过对来自pg19数据集的一本书等大量文本计算负损失似然,来测量困惑度。
在benchmark/scripts中已经准备好了各种模型架构(如Llama 2、Falcon、MPT、Mistral和GPT-NeoX(Pythia))的即用型脚本。每个脚本都会运行以下基准和绘图工具:纯transformers、attention_sinks和第三种替代方法:windowed(涉及简单窗口注意力,窗口大小为1024个token)。完成脚本后,将绘制基准发现中的图表。
benchmark目录还包含困惑度基准工具的输出目录。
运行基准脚本
基准工具
您可以使用提供的perplexity.py基准脚本运行几个基准,以计算随时间变化的各种模型的困惑度。这是通过在提供包含60k+个token的全书时计算所选模型的负对数似然损失来完成的。默认情况下,脚本在8192个token后停止,但这可以进行修改。理想解决方案持续具有低对数困惑度和恒定的CUDA VRAM使用。
要使用此脚本,您可以运行
python benchmark/perplexity.py --experiment attention_sinks
完整的参数列表
usage: perplexity.py [-h] [--experiment {attention_sinks,transformers,windowed}] [--model_name_or_path MODEL_NAME_OR_PATH] [--revision REVISION]
[--trust_remote_code] [--dataset_name DATASET_NAME] [--data_column DATA_COLUMN] [--task TASK] [--split {validation,test}]
[--num_tokens NUM_TOKENS] [--output_dir OUTPUT_DIR] [--window_size WINDOW_SIZE] [--attention_sink_size ATTENTION_SINK_SIZE]
options:
-h, --help show this help message and exit
--experiment {attention_sinks,transformers,windowed}
--model_name_or_path MODEL_NAME_OR_PATH
--revision REVISION
--trust_remote_code
--dataset_name DATASET_NAME
--data_column DATA_COLUMN
--task TASK
--split {validation,test}
--num_tokens NUM_TOKENS
--output_dir OUTPUT_DIR
--window_size WINDOW_SIZE
--attention_sink_size ATTENTION_SINK_SIZE
此脚本将在输出目录(默认为"benchmarks/outputs")中创建一个csv文件,其中包含关于困惑度、CUDA VRAM使用情况和延迟的信息。
绘图工具
可以使用plot_perplexity.py脚本绘制基准工具的信息。特别是,您可以绘制以下任何组合的特征
困惑度,vram,即CUDA VRAM使用情况延迟.
例如
python benchmark/plot_perplexity.py --features perplexity latency --title "Log perplexity & latency of Llama 2 7B as a function of input lengths"
完整的参数列表
usage: plot_perplexity.py [-h] [--output_dir OUTPUT_DIR] [--features {perplexity,vram,latency} [{perplexity,vram,latency} ...]] [--title TITLE]
[--log_perplexity_limit LOG_PERPLEXITY_LIMIT] [--skip_first SKIP_FIRST]
options:
-h, --help show this help message and exit
--output_dir OUTPUT_DIR
--features {perplexity,vram,latency} [{perplexity,vram,latency} ...]
--title TITLE
--log_perplexity_limit LOG_PERPLEXITY_LIMIT
--skip_first SKIP_FIRST
此脚本从输出目录(默认为"benchmark/outputs")中获取所有csv文件,并创建如图所示的图表
python benchmark/plot_perplexity.py --features perplexity vram --title "Log perplexity & VRAM usage of Llama 2 7B as a function of input lengths" --output_dir benchmark/outputs_llama_2_7b --log_perplexity_limit 4
无限生成过程中的流畅度
我通过使用attention_sinks、transformers和windowed模式运行demo/endless_generation.py来测量无限生成过程中的流畅度。我用Llama-2-7B-hf运行此脚本,最多10000个token,并手动观察输出,这些输出已记录在attention_sinks、transformers和windowed(注意力)中。
在我观察到流畅度下降后,我停止了生成。
对于聊天风格的LLMs,跨后续提示的流畅度
我已经通过运行demo/streaming.py来测量后续提示的流畅性,使用attention_sinks、transformers和windowed模式,并解析日志。特别是,如果根据NLTK词表自动将响应分类为失败,则其包含少于3个真实单词。响应由NLTK词标记器标记化,并转换为小写。
常见问题解答
本常见问题解答由论文作者创建
-
“处理无限长度输入”对LLM有何含义?
使用LLM处理无限长度文本具有挑战性。特别是,存储所有以前的键和值(KV)状态需要大量的内存,模型可能难以生成超过其训练序列长度的文本。Attention Sink模型通过仅保留最近标记和注意力源来解决此问题,丢弃中间标记。这使得模型能够从最近的标记生成连贯的文本,而无需刷新缓存——这是早期方法中未见到的功能。
-
LLM的上下文窗口是否被扩展?
没有。上下文窗口保持不变。仅保留最近的标记和注意力源,丢弃中间标记。这意味着模型只能处理最新的标记。上下文窗口仍然受其初始预训练的限制。例如,如果Llama-2使用4096个标记的上下文窗口进行预训练,那么Attention Sink模型在Llama-2上的最大缓存大小仍为4096。
-
我可以将大量文本,如书籍,输入到Attention Sink模型进行摘要吗?
虽然您可以输入长文本,但模型只会识别最新的标记。因此,如果一本书是输入,Attention Sink模型可能只能总结最后几段,这可能不太有洞察力。如前所述,我们既不扩展LLM的上下文窗口,也不增强其长期记忆。Attention Sink模型的优势在于从最近的标记生成流畅的文本,而无需刷新缓存。
-
Attention Sink模型的理想用例是什么?
Attention Sink模型针对流式应用进行了优化,例如多轮对话。它适用于模型需要持续运行而不需要大量内存或依赖过去数据的场景。例如,基于LLM的每日助手。Attention Sink模型可以让模型连续运行,基于最近的对话进行响应,而无需刷新其缓存。早期方法要么需要在对话长度超过训练长度时重置缓存(丢失最近上下文),要么从最近的文本历史中重新计算KV状态,这可能很耗时。
-
Attention Sink方法与最近关于上下文扩展的工作有何关系?
Attention Sink方法与最近的上下文扩展方法正交,可以与它们集成。在Attention Sink模型的情况下,“上下文扩展”是指使用更大的缓存大小来存储更多最近的标记。对于实际演示,请参阅论文中的图9,其中LongChat-7B-v1.5-32K和Llama-2-7B-32K-Instruct被适配了Attention Sinks。
变更日志
有关所有发布信息,请参阅CHANGELOG.md。
致谢
受StreamingLLM的启发并改编。
模型贡献
非常感谢以下贡献者扩展了attention_sinks的模型支持!
- @Sanster为添加对QWen模型的支持。
- @kmn1024为添加对StableLM_Epoch模型的支持。
- @MekkCyber为添加对Yi模型的支持。
引用
@article{xiao2023streamingllm,
title={Efficient Streaming Language Models with Attention Sinks},
author={Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike},
journal={arXiv},
year={2023}
}


下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。