Apache Airflow中的经济实惠的Databricks工作流程






项目描述
弃用通知
随着 0.3.0 版本的 astro-provider-databricks 包发布,此提供者已被弃用,将不再接收更新。我们建议迁移到官方的 apache-airflow-providers-databricks>= 6.8.0 以获取最新功能和支持。对于此存储库中弃用的操作符和传感器,迁移到官方 Apache Airflow Databricks 提供者,只需按照以下示例更改 DAG 代码中的导入路径即可。
| 以前使用的导入路径(现在已弃用) | 建议使用的导入路径 |
|---|---|
from astro_databricks.operators.notebook import DatabricksNotebookOperator |
from airflow.providers.databricks.operators.databricks import DatabricksNotebookOperator |
from astro_databricks.operators.workflow import DatabricksWorkflowTaskGroup |
from airflow.providers.databricks.operators.databricks_workflow import DatabricksWorkflowTaskGroup |
from astro_databricks.operators.common import DatabricksTaskOperator |
from airflow.providers.databricks.operators.databricks import DatabricksTaskOperator |
from astro_databricks.plugins.plugin import AstroDatabricksPlugin |
from airflow.providers.airflow.providers.databricks.plugins.databricks_workflow import DatabricksWorkflowPlugin |
存档
Airflow 中的 Databricks 工作流
Astro Databricks 提供者是 Apache Airflow 提供者,用于使用 Airflow 作为编写界面来编写 Databricks 工作流。将您的 Databricks 笔记本作为 Databricks 工作流运行可以导致 75% 的成本降低(通用计算 $0.40/DBU,作业计算 $0.07/DBU)。
虽然这是由 Astronomer 维护的,但任何人使用 Airflow 都可以使用它 - 您不需要成为 Astronomer 客户才能使用它。
在 Airflow 中定义您的 Databricks 工作流有以下一些优点
| 通过 Databricks | 通过 Airflow | |
|---|---|---|
| 编写界面 | 通过 Databricks UI 的基于 Web 的界面 | 通过 Airflow DAG 代码 |
| 工作流计算定价 | ✅ | ✅ |
| 笔记本代码在源代码管理中 | ✅ | ✅ |
| 工作流结构在源代码管理中 | ✅ | ✅ |
| 从头开始重试 | ✅ | ✅ |
| 重试单个任务 | ✅ | ✅ |
| 工作流内的任务组 | ✅ | |
| 从其他 DAG 触发工作流 | ✅ | |
| 工作流级别的参数 | ✅ |
示例
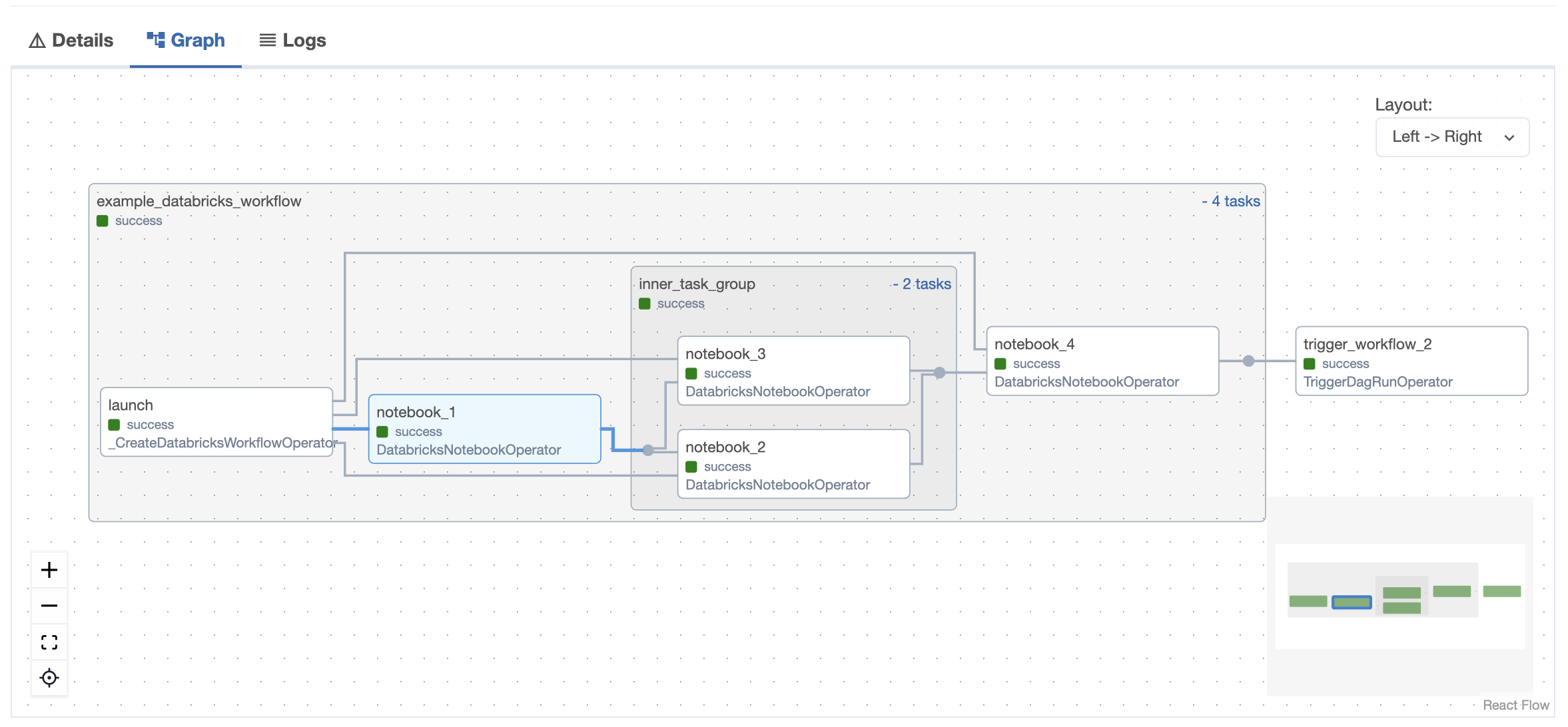
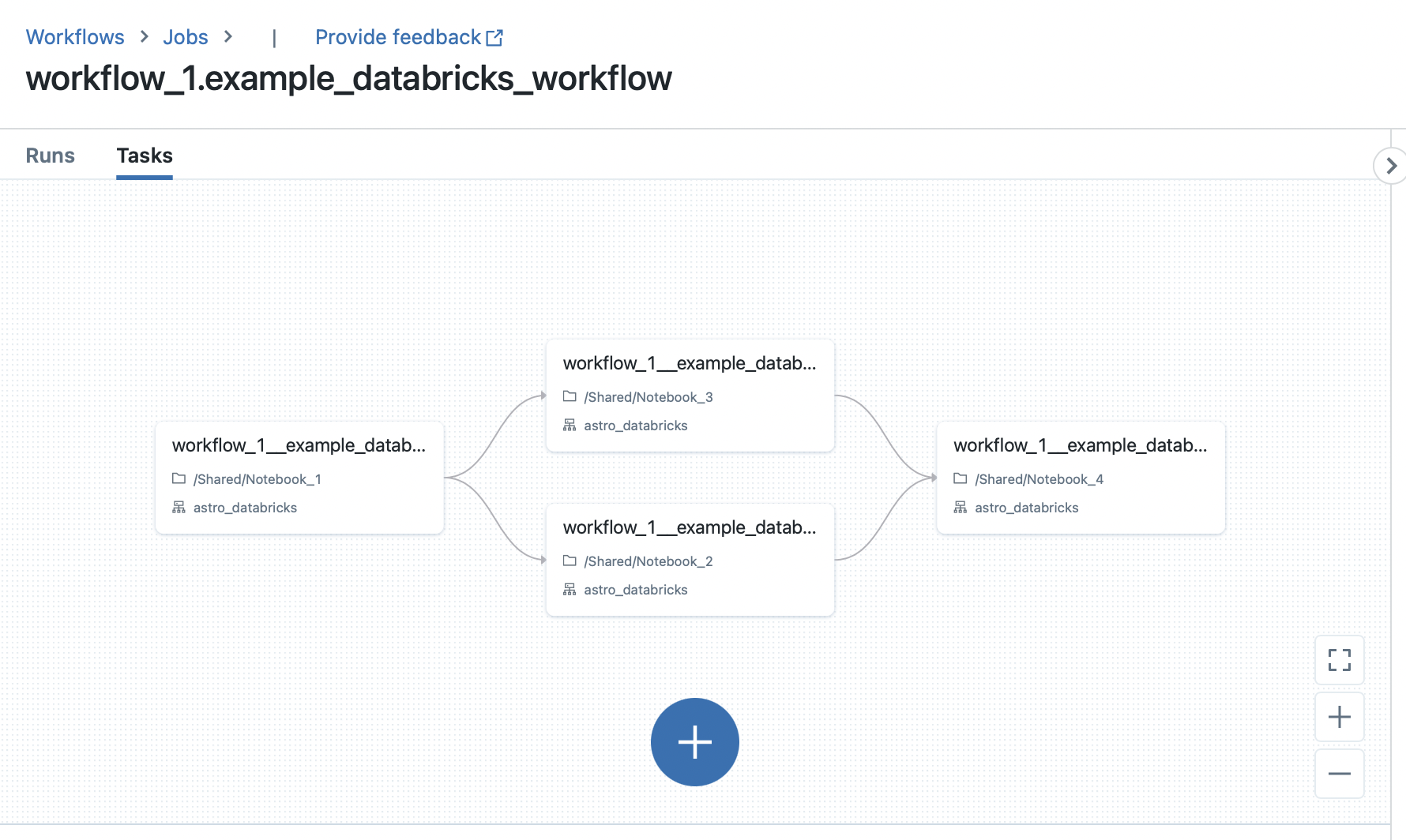
以下 Airflow DAG 说明了如何使用 DatabricksTaskGroup 和 DatabricksNotebookOperator 在 Airflow 中定义 Databricks 工作流
from pendulum import datetime
from airflow.decorators import dag, task_group
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
from astro_databricks import DatabricksNotebookOperator, DatabricksWorkflowTaskGroup
# define your cluster spec - can have from 1 to many clusters
job_cluster_spec = [
{
"job_cluster_key": "astro_databricks",
"new_cluster": {
"cluster_name": "",
# ...
},
}
]
@dag(start_date=datetime(2023, 1, 1), schedule_interval="@daily", catchup=False)
def databricks_workflow_example():
# the task group is a context manager that will create a Databricks Workflow
with DatabricksWorkflowTaskGroup(
group_id="example_databricks_workflow",
databricks_conn_id="databricks_default",
job_clusters=job_cluster_spec,
# you can specify common fields here that get shared to all notebooks
notebook_packages=[
{ "pypi": { "package": "pandas" } },
],
# notebook_params supports templating
notebook_params={
"start_time": "{{ ds }}",
}
) as workflow:
notebook_1 = DatabricksNotebookOperator(
task_id="notebook_1",
databricks_conn_id="databricks_default",
notebook_path="/Shared/notebook_1",
source="WORKSPACE",
# job_cluster_key corresponds to the job_cluster_key in the job_cluster_spec
job_cluster_key="astro_databricks",
# you can add to packages & params at the task level
notebook_packages=[
{ "pypi": { "package": "scikit-learn" } },
],
notebook_params={
"end_time": "{{ macros.ds_add(ds, 1) }}",
}
)
# you can embed task groups for easier dependency management
@task_group(group_id="inner_task_group")
def inner_task_group():
notebook_2 = DatabricksNotebookOperator(
task_id="notebook_2",
databricks_conn_id="databricks_default",
notebook_path="/Shared/notebook_2",
source="WORKSPACE",
job_cluster_key="astro_databricks",
)
notebook_3 = DatabricksNotebookOperator(
task_id="notebook_3",
databricks_conn_id="databricks_default",
notebook_path="/Shared/notebook_3",
source="WORKSPACE",
job_cluster_key="astro_databricks",
)
notebook_4 = DatabricksNotebookOperator(
task_id="notebook_4",
databricks_conn_id="databricks_default",
notebook_path="/Shared/notebook_4",
source="WORKSPACE",
job_cluster_key="astro_databricks",
)
notebook_1 >> inner_task_group() >> notebook_4
trigger_workflow_2 = TriggerDagRunOperator(
task_id="trigger_workflow_2",
trigger_dag_id="workflow_2",
execution_date="{{ next_execution_date }}",
)
workflow >> trigger_workflow_2
databricks_workflow_example_dag = databricks_workflow_example()
Airflow UI
Databricks UI
快速入门
查看以下快速入门指南
文档
该文档是工作正在进行中--我们旨在遵循 Diátaxis 系统
变更日志
Astro Databricks 遵循 语义版本控制 进行发布。阅读 变更日志 了解每个版本引入的更改的更多信息。
贡献指南
欢迎所有贡献、错误报告、错误修复、文档改进、增强和想法。
阅读 贡献指南 了解如何贡献的详细概述。
贡献者和维护者应遵守贡献者行为准则。
许可


astro_provider_databricks-0.3.0.tar.gz 的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 9f31528a4b74a2f9668245a3cbd7db204662ff47a3d69a7875604bceaa55dabc |
|
| MD5 | 50d6186c2b1963a7cd4ef11a821292f9 |
|
| BLAKE2b-256 | df100ede52a8e62931c454e5759b552c3815a48637446f3e4fb893465cee102c |
astro_provider_databricks-0.3.0-py3-none-any.whl 的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 37e0912fef1be03aee9d4841c1d1061c223aeae739035ca9ca141a48d6457c25 |
|
| MD5 | 774647d5d5c45deab9a172db256729d1 |
|
| BLAKE2b-256 | 22a06344aadea13590930035bae670b1e67c21bf900f86a020e3a2733839b177 |







