AI媒体与虚假信息内容分析工具


项目描述
AMMICO - AI媒体与虚假信息内容分析工具





此包可从包含图像部分和文本部分的社交媒体帖子等图像中提取数据。分析可以生成大量特征,具体取决于用户输入。有关更详细的描述,请参阅我们的论文。
该项目目前正在开发中!
使用预处理过的图像文件(如包含评论的社交媒体帖子)进行信息收集
- 从图像中提取文本
- 语言检测
- 翻译成英文或其他语言
- 文本清理,拼写检查
- 情感分析
- 命名实体识别
- 主题分析
- 从图像中提取内容
- 图像内容的文本摘要(“图像标题”),可以使用上述工具进一步分析
- 从图像中提取特征:用户输入查询,图像与该查询匹配(文本和图像查询)
- 问答
- 在图像中进行人员和面部识别
- 面部遮挡检测
- 年龄、性别和种族检测
- 情感识别
- 颜色分析
- 分析图像上的色调和颜色百分比
- 多模态分析
- 寻找与图像内容或图像相似度最高的匹配项
- 裁剪图像以移除帖子中的评论
安装
可以使用pip安装AMMICO包
pip install ammico
这将本地安装软件包及其依赖项。如果在安装后运行某些模块时出现错误,请按照以下说明操作。
兼容性问题解决
一些ammico组件需要tensorflow(例如情感检测器),一些pytorch(例如摘要检测器)。有时这两个框架之间会有兼容性问题。为了避免这些问题,您可以在安装软件包之前准备适当的环境(您的机器上需要conda)。
1. 首先,安装tensorflow(https://tensorflowcn.cn/install/pip)
-
创建一个包含python的新环境并激活它
conda create -n ammico_env python=3.10conda activate ammico_env -
从conda-forge安装cudatoolkit
conda install -c conda-forge cudatoolkit=11.8.0 -
使用pip安装nvidia-cudnn-cu11
python -m pip install nvidia-cudnn-cu11==8.6.0.163 -
添加当conda环境
ammico_env激活时运行的脚本,将正确的库放在您的LD_LIBRARY_PATH上mkdir -p $CONDA_PREFIX/etc/conda/activate.d echo 'CUDNN_PATH=$(dirname $(python -c "import nvidia.cudnn;print(nvidia.cudnn.__file__)"))' >> $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh echo 'export LD_LIBRARY_PATH=$CUDNN_PATH/lib:$CONDA_PREFIX/lib/:$LD_LIBRARY_PATH' >> $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh source $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh -
取消激活并重新激活conda环境以调用上述脚本
conda deactivateconda activate ammico_env -
安装tensorflow
python -m pip install tensorflow==2.12.1
2. 第二步,安装pytorch
-
安装与上面相同的cuda版本的pytorch
python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
3. 准备好正确的环境后,我们可以安装ammico软件包
python -m pip install ammico
完成。
Micromamba
如果您使用micromamba,您可以使用一条命令准备环境
micromamba create --no-channel-priority -c nvidia -c pytorch -c conda-forge -n ammico_env "python=3.10" pytorch torchvision torchaudio pytorch-cuda "tensorflow-gpu<=2.12.3" "numpy<=1.23.4"
Windows
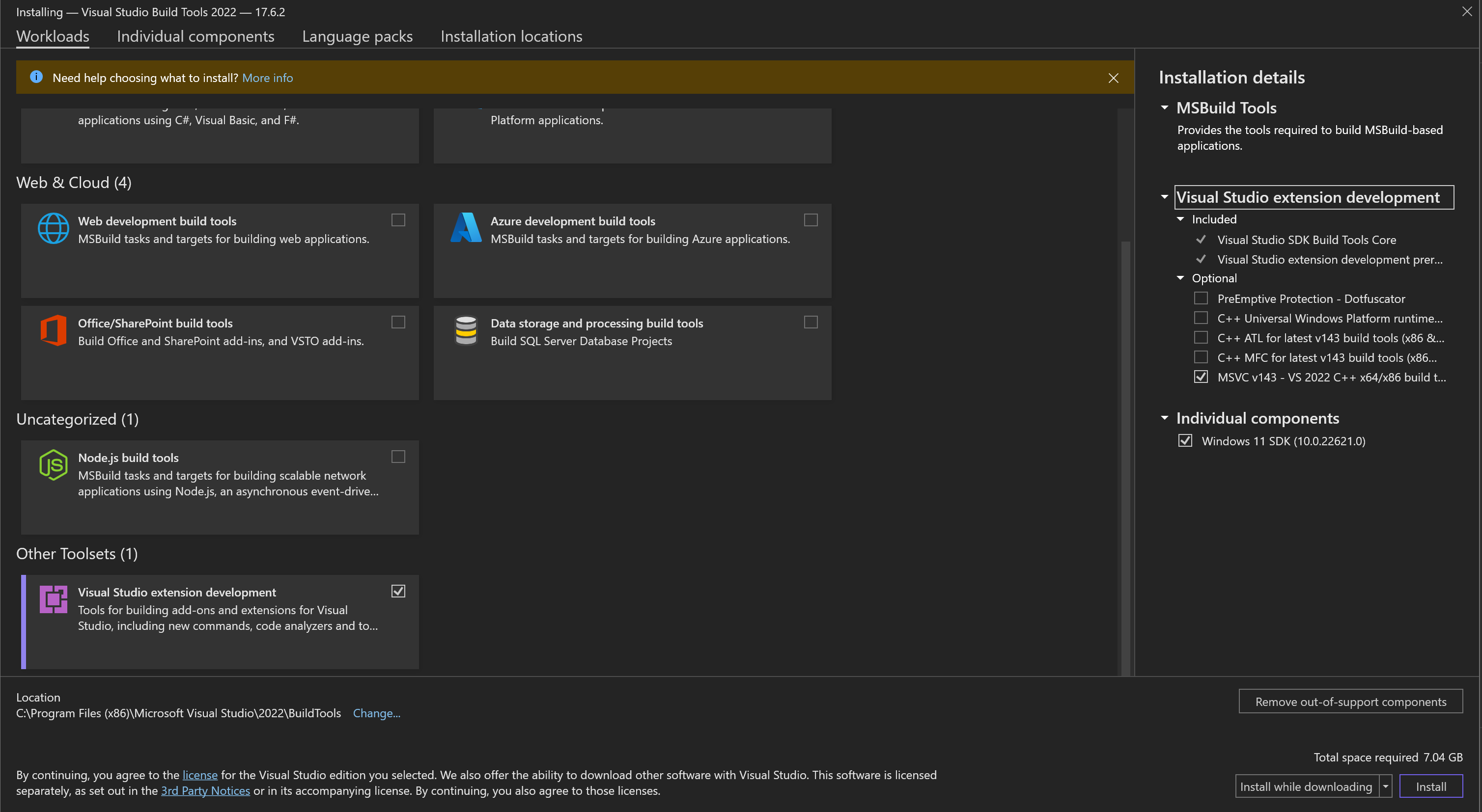
为了使pycocotools在Windows OS上工作,您可能需要从https://visualstudio.microsoft.com/visual-cpp-build-tools/安装vs_BuildTools.exe,并选择以下元素
Visual Studio扩展开发MSVC v143 - VS 2022 C++ x64/x86构建工具- Windows 11 SDK(针对Windows 11)(或Windows 10 SDK针对Windows 10)
请注意,它需要大约7GB的磁盘空间。
使用方法
主要演示笔记本位于notebooks文件夹中,也可以在google colab上找到。
notebooks文件夹中还有更多用于更实验性功能的示例笔记本。
- 主题分析:使用笔记本
get-text-from-image.ipynb分析提取文本的主题。
您可以在google colab上运行此笔记本:这里
将数据文件和google cloud vision API密钥放在您的google drive中以访问数据。 - 使用
cropposts.ipynb笔记本裁剪社交媒体帖子。您可以在google colab上运行此笔记本:这里
功能
文本提取
使用google-cloud-vision从图像中提取文本。为此,您需要一个API密钥。按照谷歌视觉AI网站上的说明设置您的谷歌账户或如这里所述。然后,您需要将API密钥的位置导出为环境变量
export GOOGLE_APPLICATION_CREDENTIALS="location of your .json"
提取的文本存储在text键下(当导出为csv时的列)。
使用Googletrans自动识别语言并将其翻译成英语。文本语言和翻译文本存储在text_language和text_english键下(当导出为csv时的列)。
如果您想进一步分析文本,您需要将 analyse_text 关键字设置为 True。这样做后,文本将使用 spacy(分词、词性标注、词干提取等)进行处理。英文文本将被清理掉数字和无法识别的单词(text_clean),并更正英文文本的拼写(text_english_correct),然后进行进一步的语义分析和主观性分析(polarity,subjectivity)。后两步使用 TextBlob 实现。有关使用 TextBlob 进行语义分析的信息,请参见这里。
使用 Hugging Face transformers 库 来执行另一种语义分析、文本摘要和命名实体识别,使用 transformers 管道。
内容提取
使用 LAVIS 库提取图像内容(“标题”)。这个库允许根据任务使用多个最先进的模型来提取视觉智能,此外,它允许从图像中提取特征,用户可以输入文本和图像查询,并将数据库中的图像与该查询进行匹配(多模态搜索)。另一种选择是问答,用户输入文本问题,库会找到与查询匹配的图像。
情感识别
使用 deepface 和 retinaface 库进行情感识别。这些库基于多个最先进的模型检测人脸的存在、年龄、性别、情绪和种族。还可以检测到人是否佩戴口罩——如果佩戴,则不会进行进一步的检测,因为口罩会阻止准确预测。
颜色/色调检测
使用 colorgram.py 和 colour 进行颜色检测,用于距离度量。颜色可以分类为英语中主要的命名颜色/色调,包括红色、绿色、蓝色、黄色、青色、橙色、紫色、粉色、棕色、灰色、白色、黑色。
帖子裁剪
社交媒体帖子可以自动裁剪,以删除页面上的其他评论,并将文本内容仅限于第一条评论。
常见问题解答
发送到 Google Cloud Vision 的图像会发生什么?
根据 Google Vision API,上传并分析的图像不会存储,也不会与第三方共享。
我们不会将您发送的内容公开。我们不会与任何第三方共享内容。内容仅用于谷歌提供视觉 API 服务所需。视觉 API 遵守云数据处理附加协议。
对于在线(即时响应)操作(
BatchAnnotateImages和BatchAnnotateFiles),图像数据在内存中处理,不会持久化到磁盘。对于异步离线批量操作(AsyncBatchAnnotateImages和AsyncBatchAnnotateFiles),我们必须将图像存储一段时间,以便进行分析并将结果返回给您。存储的图像通常在处理完毕后立即删除,具有几个小时的容错生存时间(TTL)。谷歌还临时记录一些关于您的视觉 API 请求的元数据(例如请求接收的时间等)以改进我们的服务并打击滥用。
发送到 Google 翻译的文字会发生什么?
根据 Google 翻译,翻译处理后的数据不会存储,也不会提供给第三方。
我们不会将您发送的文本内容公开。我们不会与任何第三方共享内容。文本内容仅由谷歌在提供云翻译API服务时按需使用。云翻译API符合云数据处理附加协议。
当您向云翻译API发送文本时,文本将在内存中短暂存储,以便执行翻译并将结果返回给您。
如果没有互联网连接,我还能使用ammico吗?
ammico的一些功能需要互联网连接;对此问题无法给出一般性的回答,一些服务需要网络连接,而其他功能可以在离线状态下使用。
- 文本提取:要从图像中提取文本并进行翻译,需要由谷歌云视觉和谷歌翻译处理这些数据,这些服务在云端运行。没有互联网连接,无法进行文本提取和翻译。
- 图像摘要和查询:在初始下载模型之后,
summary模块不需要互联网连接。 - 面部表情:在初始下载模型之后,
faces模块不需要互联网连接。 - 多模态搜索:在初始下载模型之后,
multimodal_search模块不需要互联网连接。 - 颜色分析:
color模块不需要互联网连接。


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源分发
构建分发
ammico-0.2.1.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 9456adabe9fa3de5d71355e3c65e533f791ed68075d21e2653bee3f4959c2df1 |
|
| MD5 | 82ec758b770fbb146b05cfeeac9155fa |
|
| BLAKE2b-256 | 623fbeee2e933e4c3ee3cda8d4408d3d91239b9be896759f79cc37c2479869aa |
ammico-0.2.1-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | ed0c6f71500a6d988100df41adbce8aa734cf3bc06845a91558d8d276353085f |
|
| MD5 | d02a51364dde69fb1b7583a5a162f4fe |
|
| BLAKE2b-256 | ad6389c83f4aa27db351310c15a945e42b835f603c0f1d99d564c56229ef9b70 |







