数学函数的并行主动学习


项目描述
 自适应:数学函数的并行主动学习 :brain::1234
自适应:数学函数的并行主动学习 :brain::1234










自适应是一个开源的Python库,它简化了自适应并行函数评估。它不是在密集网格上计算所有点,而是根据您提供的函数和界限,智能地选择参数空间中的“最佳”点。用最少的代码,您可以在计算集群上执行评估,显示实时绘图,并优化自适应采样算法。
由于选择潜在有趣点的开销,自适应在每次函数评估至少需要≈50ms的计算中效率最高。
要查看自适应功能,请尝试访问 Binder上的示例笔记本,或探索 Read the Docs上的教程。
[目录] 📚
:star: 关键特性
- 🎯 智能自适应采样:Adaptive关注函数中的兴趣区域,通过更少的评估获得更好的结果,节省时间和计算资源。
- ⚡ 并行执行:该库利用并行处理进行更快的函数评估,充分利用可用的计算资源。
- 📊 实时绘图和信息小部件:在Jupyter笔记本中工作,Adaptive提供学习过程的实时可视化,使其更容易监控进度并确定改进区域。
- 🔧 可定制损失函数:Adaptive支持各种损失函数,并允许自定义,使用户能够根据其特定需求定制学习过程。
- 📈 多维函数支持:该库可以处理一维或多维中具有标量或向量输出的函数,为各种问题提供灵活性。
- 🧩 无缝集成:Adaptive提供简单直观的界面,使其易于集成到现有的Python项目和工作中。
- 💾 灵活的数据导出:该库提供将学习数据导出为NumPy数组或Pandas DataFrame的选项,确保与各种数据处理工具的兼容性。
- 🌐 开源和社区驱动:Adaptive是一个开源项目,鼓励社区贡献,以持续改进和扩展库的功能和能力。
:rocket: 示例用法
在Jupyter笔记本中自适应地学习一维函数并实时绘制过程
from adaptive import notebook_extension, Runner, Learner1D
notebook_extension()
def peak(x, a=0.01):
return x + a**2 / (a**2 + x**2)
learner = Learner1D(peak, bounds=(-1, 1))
runner = Runner(learner, loss_goal=0.01)
runner.live_info()
runner.live_plot()
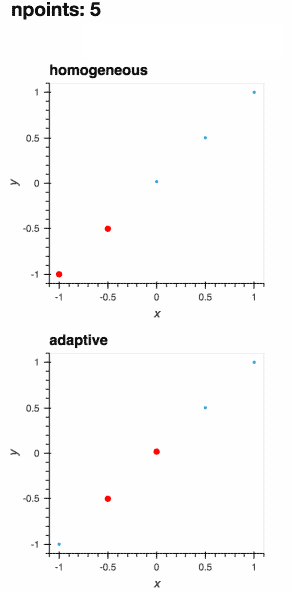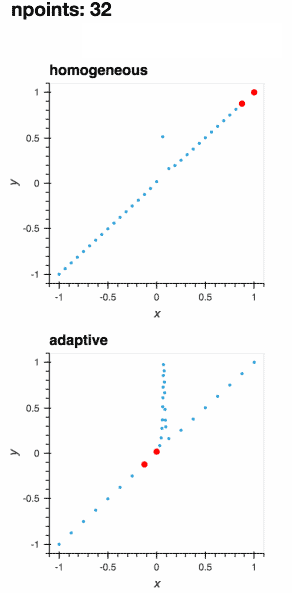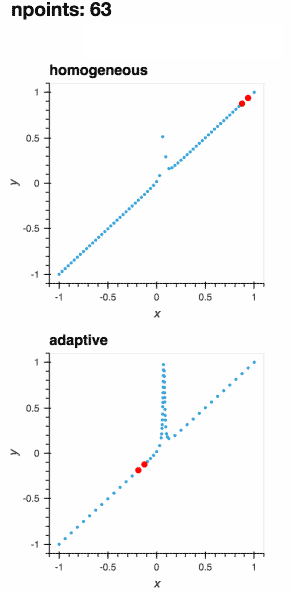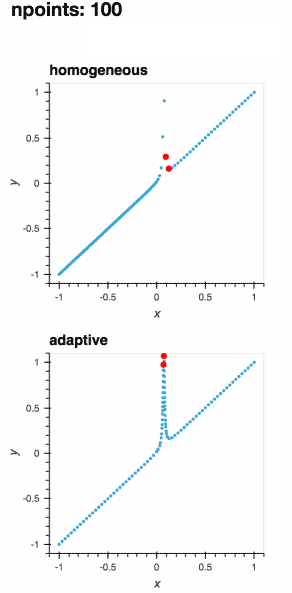
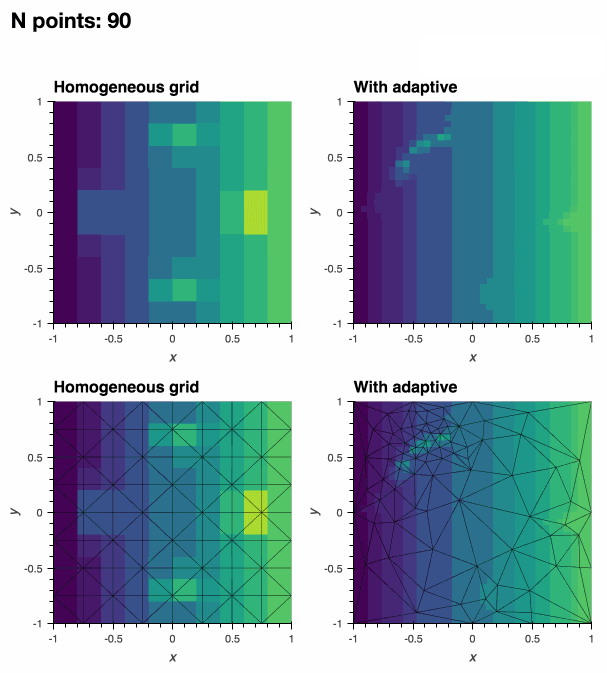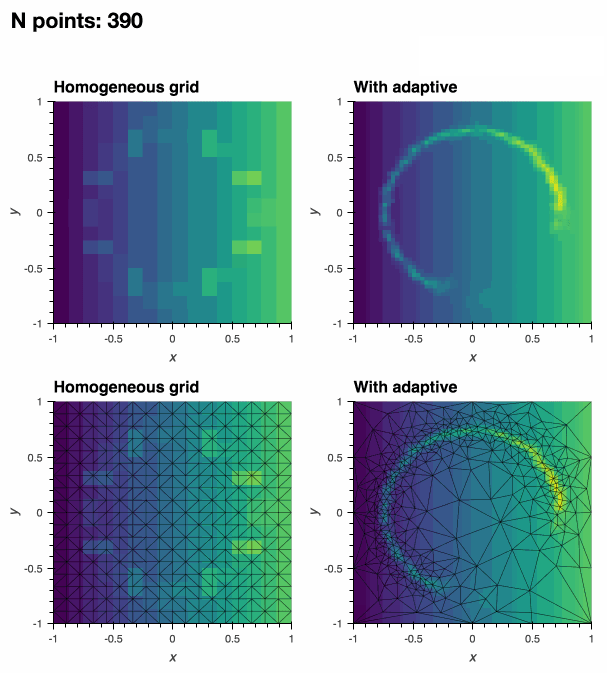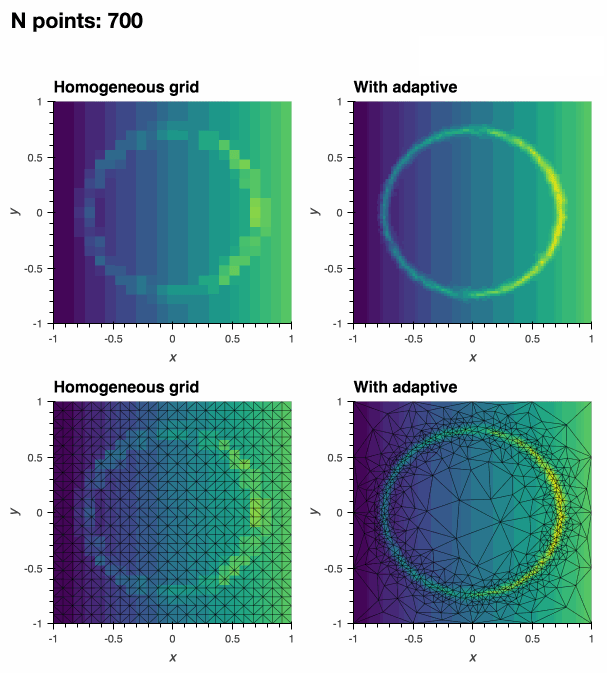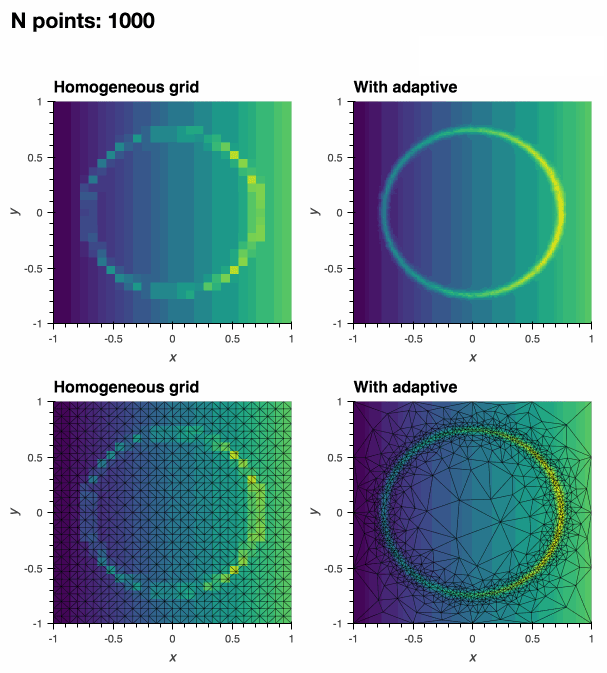
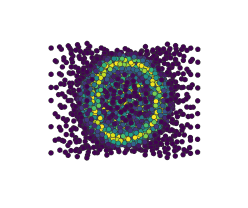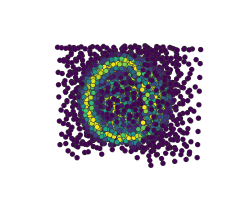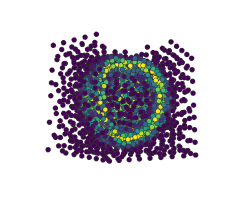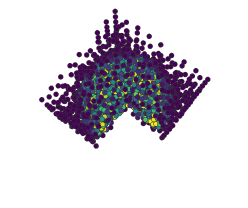
:floppy_disk: 数据导出
您可以将学习数据导出为NumPy数组
data = learner.to_numpy()
如果您已安装Pandas,您还可以将数据导出为DataFrame
df = learner.to_dataframe()
:test_tube: 实现的算法
adaptive 的核心概念是 学习器。学习器在其参数空间中最有趣的位置采样函数,允许对函数进行最佳采样。随着在更多点上评估函数,学习器会提高其理解最佳采样位置的能力。
"最佳位置"的定义取决于您的应用领域。虽然 adaptive 提供了合理的默认选择,但自适应采样过程可以完全自定义。
以下实现了以下学习器:
Learner1D:用于一维函数f: ℝ → ℝ^N,Learner2D:用于二维函数f: ℝ^2 → ℝ^N,LearnerND:用于多维函数f: ℝ^N → ℝ^M,AverageLearner:用于随机变量,允许对多次评估的结果进行平均,AverageLearner1D:用于随机一维函数,估计每个点的平均值,IntegratorLearner:用于积分一维函数f: ℝ → ℝ,BalancingLearner:用于同时运行多个学习器,并在收集更多点时选择"最佳"的一个。
元学习器(与其他学习器一起使用)
BalancingLearner:同时运行几个学习器,每次获得更多点时选择"最优化"的一个,DataSaver:当您的函数返回的不是只有标量或向量时使用。
除了学习器之外,adaptive 还提供跨多个核心或机器的并行采样的原语,内置支持:concurrent.futures、mpi4py、loky、ipyparallel 和 distributed。
:package: 安装
自适应支持在Linux、Windows或Mac上的Python 3.7及以上版本,并为使用Jupyter/IPython Notebook提供可选扩展。
推荐使用conda来安装自适应。
conda install -c conda-forge adaptive
自适应也可在PyPI上找到。
pip install "adaptive[notebook]"
上述的[notebook]将安装运行自适应在Jupyter笔记本中的可选依赖项。
要在Jupyterlab中使用自适应,您需要安装以下labextensions。
jupyter labextension install @jupyter-widgets/jupyterlab-manager
jupyter labextension install @pyviz/jupyterlab_pyviz
:wrench: 开发
克隆存储库并运行pip install -e ".[notebook,testing,other]"以将克隆的存储库添加到您的Python路径中。
git clone git@github.com:python-adaptive/adaptive.git
cd adaptive
pip install -e ".[notebook,testing,other]"
我们建议在自适应开发期间使用Conda环境或virtualenv进行包管理。
为了避免笔记本输出污染历史记录,运行以下命令设置git过滤器:
python ipynb_filter.py
在存储库中。
为了保持一致的代码风格,我们使用pre-commit。通过运行以下命令来安装它:
pre-commit install
在存储库中。
:books: 引用
如果您在科学工作中使用了自适应,请按照以下方式引用。
@misc{Nijholt2019,
doi = {10.5281/zenodo.1182437},
author = {Bas Nijholt and Joseph Weston and Jorn Hoofwijk and Anton Akhmerov},
title = {\textit{Adaptive}: parallel active learning of mathematical functions},
publisher = {Zenodo},
year = {2019}
}
:page_facing_up: 草稿论文
如果您对自适应的科学背景和原理感兴趣,我们建议您查看目前正在撰写的草稿论文。这篇论文全面概述了自适应库的概念、算法和应用。
:sparkles: 致谢
我们要感谢以下人员
- Pedro Gonnet对他实现的CQUAD,即“算法4”,如P. Gonnet在“使用显式插值提高自适应求积的可靠性”中所述,ACM Transactions on Mathematical Software,37 (3),文章编号26,2010。
- Pauli Virtanen的
AdaptiveTriSampling脚本(由于SciPy Central关闭而不再在线)是adaptive.Learner2D的灵感来源。
对于一般讨论,我们有一个Gitter聊天频道。如果您发现任何错误或有任何功能建议,请提交GitHub 问题或提交拉取请求。


下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解更多关于安装软件包的信息。
源分布
构建分布
adaptive-1.3.0.tar.gz的散列值
| 算法 | 散列值 | |
|---|---|---|
| SHA256 | 7790862b663bf8587f1bbb1ee7a851085765da2967a7d29babe197da401829fd |
|
| MD5 | 58645b4e90e9187c34a9f429f25ce592 |
|
| BLAKE2b-256 | 248e3bc7241d5e0e2133678e7f0a8cacdbefae8b2629fff787e1196ebc546b40 |
adaptive-1.3.0-py3-none-any.whl的散列值
| 算法 | 散列值 | |
|---|---|---|
| SHA256 | e18684f5dcf111bf1af0d2df66976918971b9b881a6bb72b7ff0924c0662f2dd |
|
| MD5 | 31f1eca47b325bab6c13f343319b76db |
|
| BLAKE2b-256 | 6cd83c68d419026870d671c8a957095eedd4247e6f1139153f7badafe5c1d072 |







